Design Google Drive
Propose high-level design and get buy-in
Storage type
For storage type, we can either choose file storage, block storage or object storage. Consider Block Storage vs File Storage vs Object Storage.
In our case, because of the fact that we just need our system to store the file, Object Storage is the best for its scalability and highly available.
By controlling the object, we can also implement Erasure Coding for a better redundancy and space-saving
We can have a Block servers in between to handle object creation. By using object storage, we can enable Resumable Upload.
API
For our api, we can consider The right way to UPLOAD a file using REST by separating:
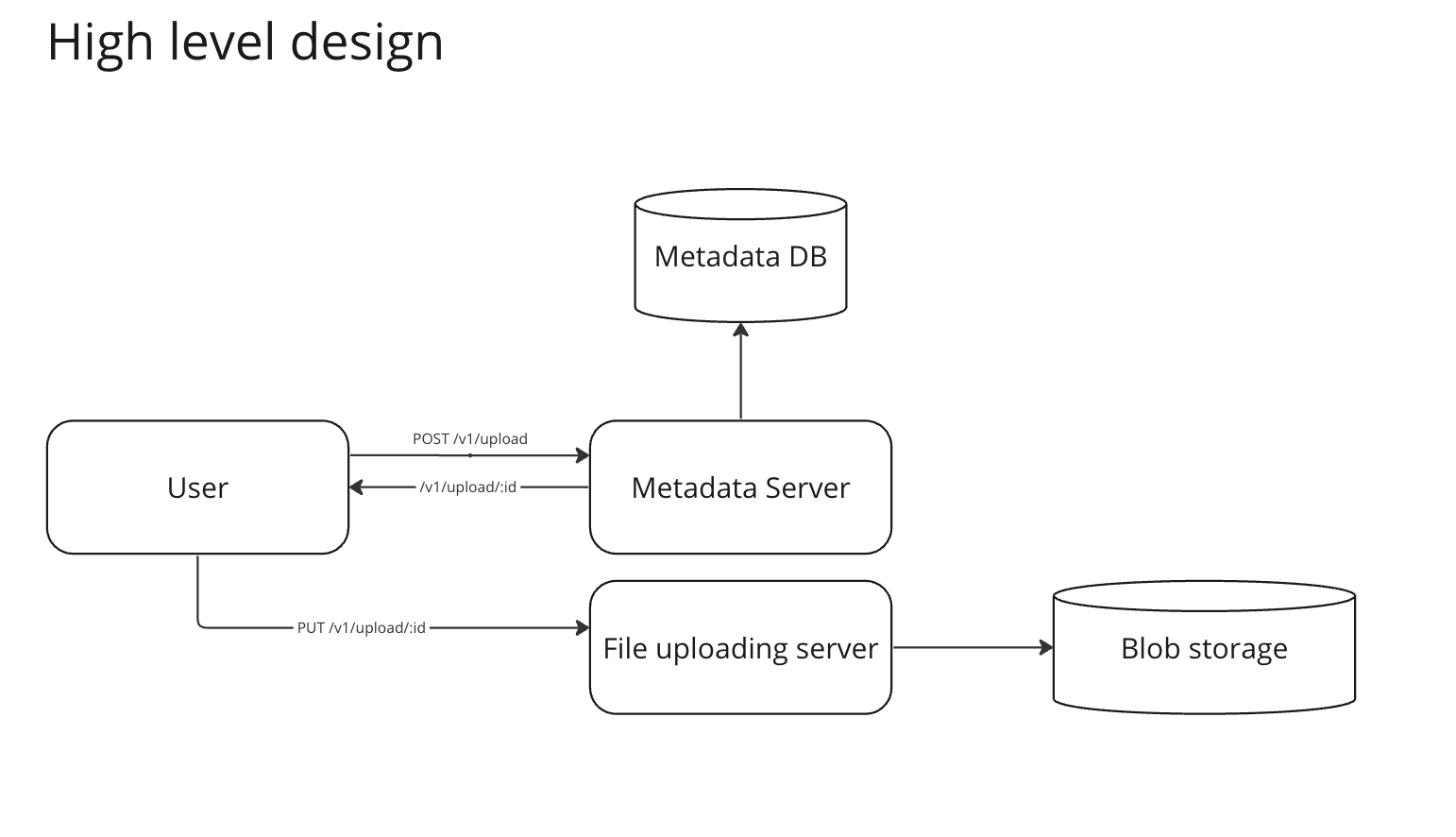
- A route for uploading the meta-data
POST /v1/upload - A route for uploading the file
PUT /v1/upload/:id
We can consider S3 Pre-signed URL in case that we're using S3 and want to upload directly to S3 bucket without going through a server.
Sync conflict
When mutliple devices of the same account trying to sync, there will be conflict. Consider strategy for Sync Conflict resolution
High level design
Low level design
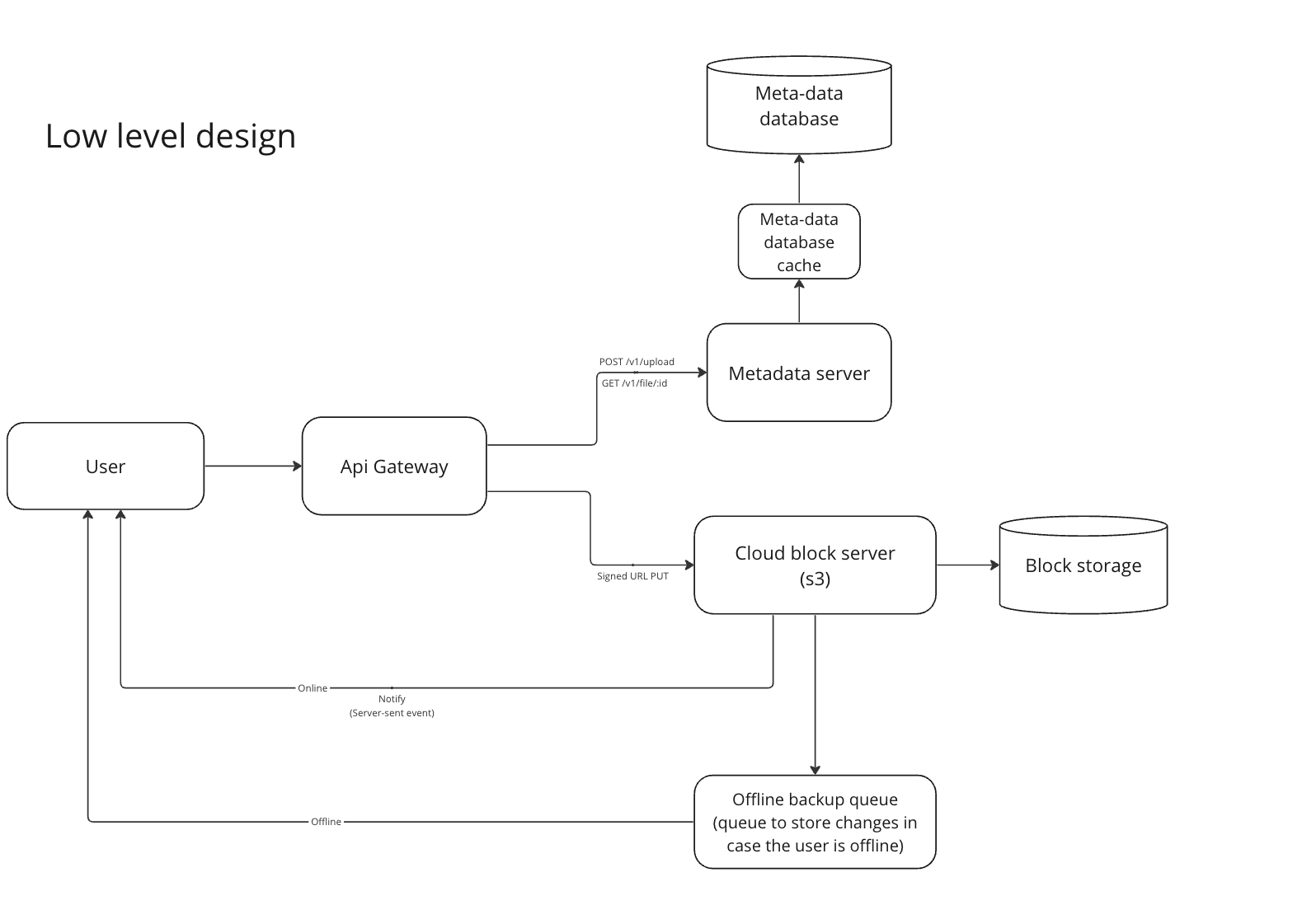
In here, API Gateway can be used for:
- Load balancing between routes
- Handle caching
For Meta-data database, we can adopt a cache pattern for high-frequency access. Depends on our requirement, we can choose either SQL vs NoSQL.
In this case, because high consistency is required, we choose Database/SQL.
In term of cache strategy, a Read Through is chosen for simplicity, for a fine-grain control, we can consider Cache-Aside Caching > Caching strategies.
Here we decided to upload straight to Cloud Storage (s3) using S3 Pre-signed URL, however it's not recommend if we need a custom encryption.
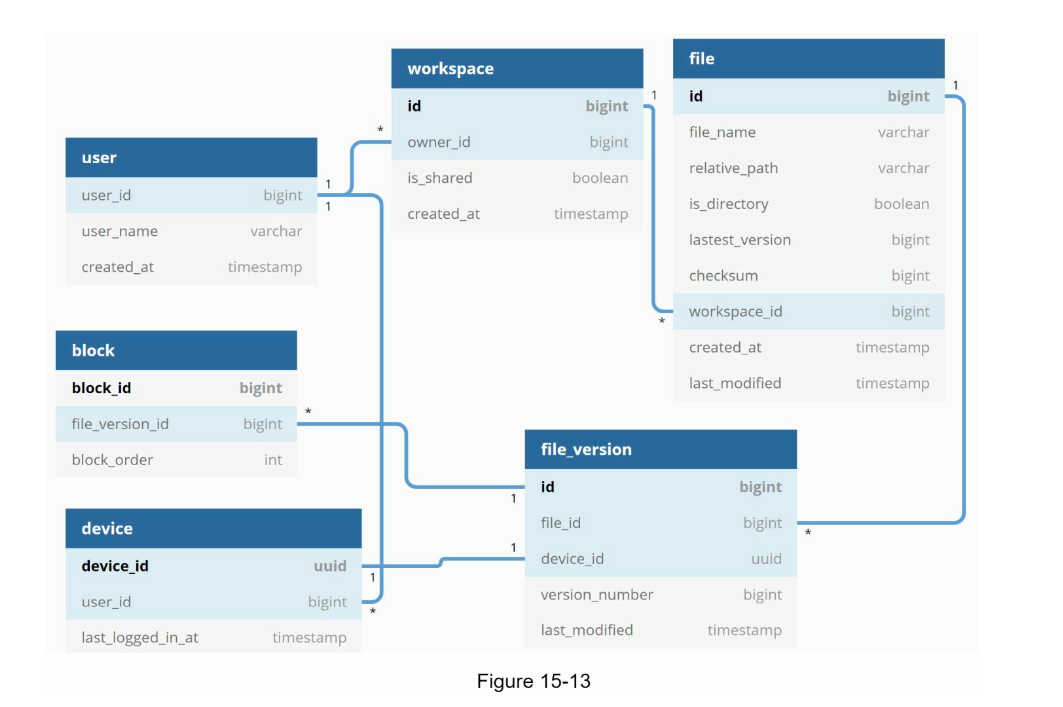
Database Schema
The meta-data database can be designed as follows:
Upload Flow
In the case an user have 2 devices (2 clients), the flow can be done as follows:
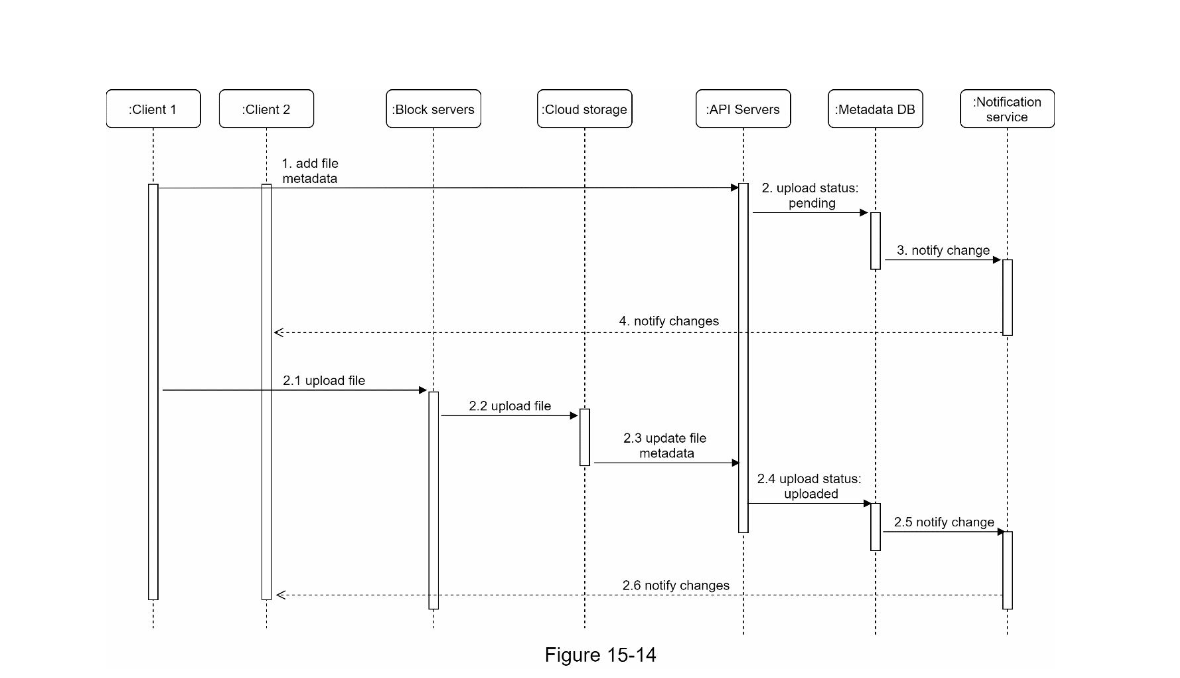
For Resumable Upload, consider the mentioned document. Note that in here we also follows The right way to UPLOAD a file using REST
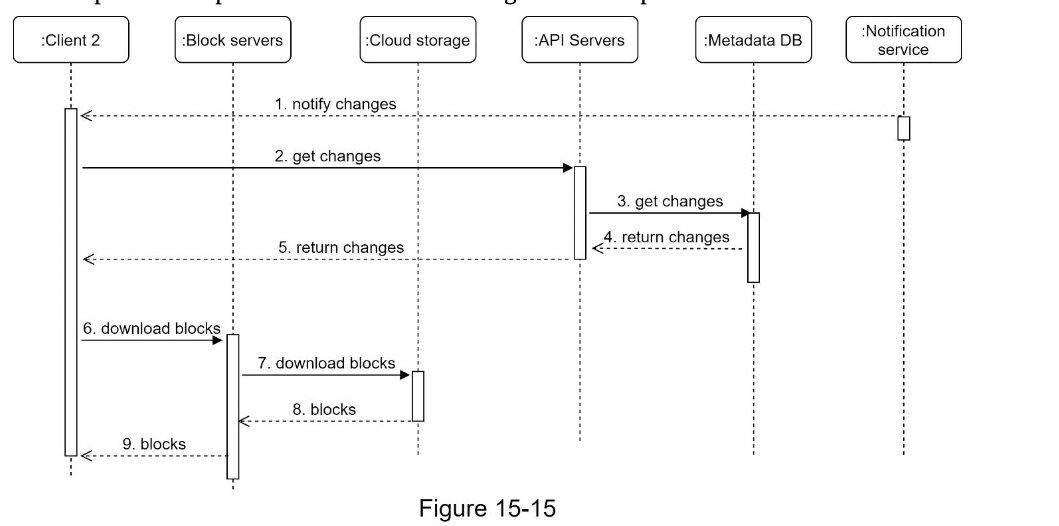
Download Flow
For downloading, if we use object storage, we only need to download the missing object.
Notification service
We have a few options:
Long polling will works with legacy devices, however, Server-Sent Events (SSE) will be more efficient.
Saving storage space strategy
There are several ways
- Set a limit how many version to store and remove the old versions.
- Moving infrequent data to cold storage (ex: Amazon Glacier)
Failure handling
Meta-data Server Fail
A secondary instance would come and pick up the traffic. We detect failure via heart beats because of our API Gateway also acts as Load balancer
Block-server Fail
Other server will pick up the job because of load balancer
Cloud storage Fail
Since S3 by default is replicated in different regions and using Erasure Coding to patch the failure, AWS will handle this for us
Meta-data cache Fail
Consider having replication for our cache.
Meta-data DB Fail
Depends on the database:
- Master fail: Promote a slave to Master and bring up a new slave node
- Slave fail: bring up another slave
Notification server fail
We keep track of a queue for changes, since Server-Sent Events (SSE) will automatically re-establish the connection once it's up again, we can send and update the mismatched events.
If using Long-polling, we need to be able to reconnect the lost connections to a different server.
Upload directly to cloud storage or not
We can use S3 Pre-signed URL to upload directly to our cloud storage. This doesn't work well if we need to implement our custom encryption.
Since client side is easy to be hacked or manipulated, it's not ideal to implement encryption at client side.
In the case that we need to handle our own encryption, consider using Block servers to do the encryption, chunk splitting, etc…