Zookeeper
A software that would help to manage the distributed system in synchronisation of data and configuration.
It works as a file system of its owns (znode) where the distributed system can read that file (znode) for informations. And they can parallely access it. Without zookeeper, distributed systems are prone to race conditions and deadlock.
Zookeeper data is keep in memory for high throughput and low latency.
Multiple Zookeepers clusters are called ensemble By default minimum of 3 zookeeper are required
Artchitecture
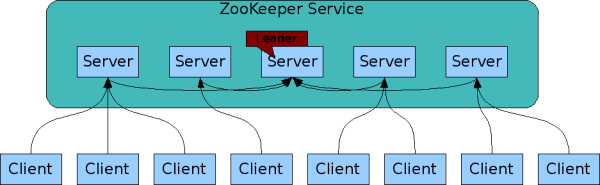
For each zookeeper service, zookeeper itself is running on each marchine. Each maintain
- In-memory image of state
- Transaction logs
- Logs are ordered with timestamps.
- Snapshot
Client will connect to one of the zookeeper server. If the connection breaks, client automatically connect to another zookeeper server.
Data model and hierarchical namespace
Namespace is separated by /. Every node in Zookeeper's is identified by a path.
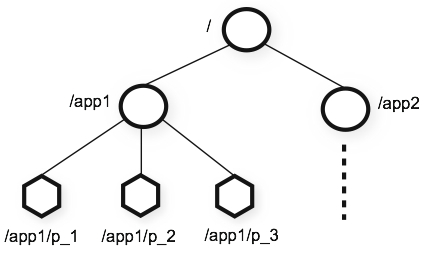
Each node here are called znode which maintain statistics include:
- version number
- Each time the znode's data changes, the version nuimber increase
- ACL changes
- Each znode has a ACL (Access Control Lists) to restrict who can do what
- timestamps
Data in this node is written atomically:
- Reads get all the data
- Write replace all the data
A node can also be ephermeral znodes
Watches
znode support watches — client can watch a znode, a watch will triggered and removed when znode changes. If the connection between the client and server is broken, client will receive a local notification
Implementation
This diagram shows the implementation for each Zookeeper service (the one that replicate on each machine)
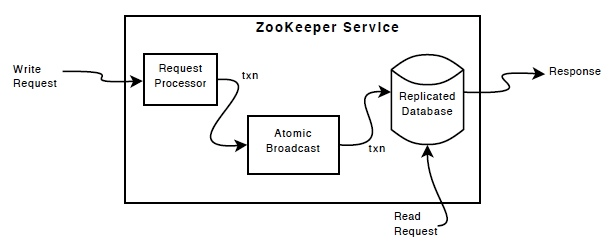
- Replicated Database: In memory database containing the entire znode trees. Updates are logged to disk for recoverability. All updates are logged into the log file first, and then apply to in-memory database
- Read request from client will read from replicated database.
- Write request are processed by the leader. Other followers receive the message proposals from reader and update accordingly
==The messaging layer is atomic so the local replicas never diverge==. All writes are put into its transaction so that it happen at once
API
- create : creates a node at a location in the tree
- delete : deletes a node
- exists : tests if a node exists at a location
- get data : reads the data from a node
- set data : writes data to a node
- get children : retrieves a list of children of a node
- sync : waits for data to be propagated
Use case
- Configurations in distributed system
- Share information in distributed system
- Control and manage the behavior of master and slaves
- Synchronisation for distributed system
- Use in Kafka
Performance
Zookeeper is perform well in ==a heavy read system since write we need to synchronise==
Zookeeper is Strong Consistency Model. Unlike Redis which is a eventually consistent model