WordSearch II
Given an m x n board of characters and a list of strings words, return all words on the board.
Each word must be constructed from letters of sequentially adjacent cells, where adjacent cells are horizontally or vertically neighboring. The same letter cell may not be used more than once in a word.
Example 1
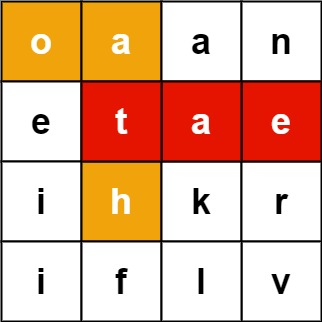
Input: board = [["o","a","a","n"],["e","t","a","e"],["i","h","k","r"],["i","f","l","v"]], words = ["oath","pea","eat","rain"]
Output: ["eat","oath"]
Example 2
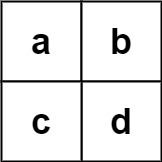
Input: board = [["a","b"],["c","d"]], words = ["abcb"]
Output: []
Solution
This question focusing on how to use a Trie and search recursively within a Trie.
Intuition
Considering the following example:
Input: board = [["o","a","a","n"],["e","t","a","e"],["i","h","k","r"],["i","f","l","v"]]
words = ["oath","pea","eat","rain"]
Output: ["eat","oath"]
To solve this problem
- We can start building a Trie of each word
- We can start doing graph traversal dfs at each cell of the
boardand check if we can form any words from our Trie.
Gotcha
In here, for example if we have

Let ssay our given word is
eaabcdfga
The DFS will traverse as the following direction:
Visit
e— since we haveeas the root in our Trievisit
a— since ourais the next candidate in our Trie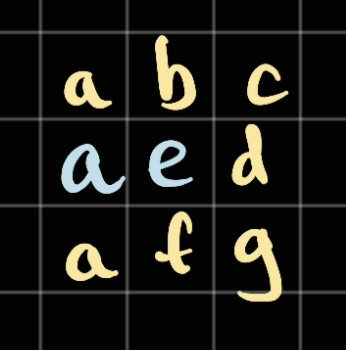
Note: in here we mark the blue one visitedNow we have to visit another
a, let's assume it chose the one below.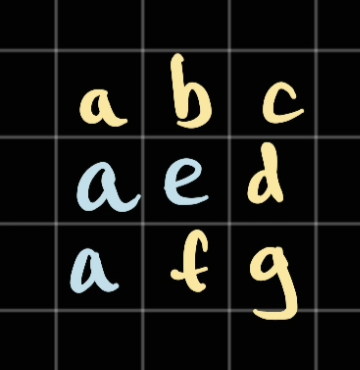
Here we look for the next character which is
b, however there is nobhere. As a result, we will go to the top one:

Fast forward, we go to visit
...bcdfga, let's mark this path as theredcolour:
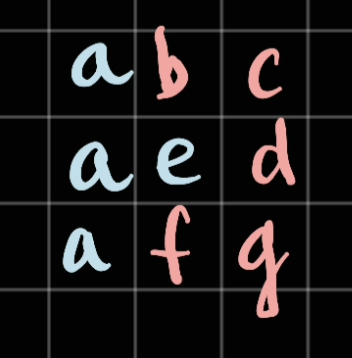
As we can see, we cannot see the last
asince the letter is already visited. Therefore, we will need to pop out the visitedaif we can't process further.
Implementation
from collections import defaultdict
from dataclasses import dataclass
from typing import *
import unittest
@dataclass
class TrieNode:
value: int
neighbours: Dict[str, 'TrieNode']
isWord: bool
numberOfCharacters: int
def __init__(self, value):
self.value = value
self.neighbours = {} # " { a : TrieNode(a) }"
self.isWord = False
self.numberOfCharacters = 0
def insertWord(self, word: str) -> None:
currNode = self
for char in word:
if char not in currNode.neighbours:
currNode.neighbours[char] = TrieNode(char)
currNode = currNode.neighbours[char]
currNode.numberOfCharacters += 1
currNode.isWord = True
def pruneTree(self, word):
# Pruning the tree once we finished searching for a word to reduce time for next word
currNode = self
for letter in word:
currNode = currNode.neighbours[letter]
currNode.numberOfCharacters -= 1
class App:
def __init__(self):
self.result = None
def findWords(self, board: List[List[str]], words: List[str]) -> List[str]:
root = TrieNode("*")
self.root = root
for word in words:
root.insertWord(word)
self.result = []
for row in range(len(board)):
for col in range(len(board[0])):
self.searchWord(board, row, col, root, set(), [])
return self.result
def searchWord(self, board: List[List[str]], row: int, col: int, currNode: TrieNode, visited: Set[Tuple[int, int]] = set(), word: List[str] = []):
if currNode.isWord:
self.result.append("".join(word))
currNode.isWord = False # avoid duplication
self.root.pruneTree(word)
if currNode.numberOfCharacters == 0 and currNode != self.root: # need currNode != self.root condition because by default starts with 0
return
if not self.withinBoundary(board, row, col, visited):
return
letter = board[row][col]
if letter not in currNode.neighbours: return
visited.add((row, col))
word.append(letter)
for dr, dc in [(1, 0), (-1, 0), (0, 1), (0, -1)]:
self.searchWord(board, row + dr, col + dc, currNode.neighbours[letter], visited, word)
visited.remove((row, col))
word.pop()
def withinBoundary(self, board, row, col, visited):
return not (row < 0 or col < 0 or col >= len(board[0]) or row >= len(board) or (row, col) in visited)
Time complexity: $O(n \times L + rows \times cols \times 4^L)$
- We have $n$ is the length of the
- $L$ is the length of the longest word
- $4^L$ is because for each
row,col, we need to search 4 direction.
Note:
- At the end of the node we need to do a
visited.pop()to release the node out for the next use, because potientially we need to reuse this letter - When we find the node, we mark the node
isWord = Falseso that we don't readding it to theresultanymore next time we found it. - We're adding
pruneTreehere, which means to reduce the number of nodes in theTrieso that next time it search quicker.