Design A Web Crawler
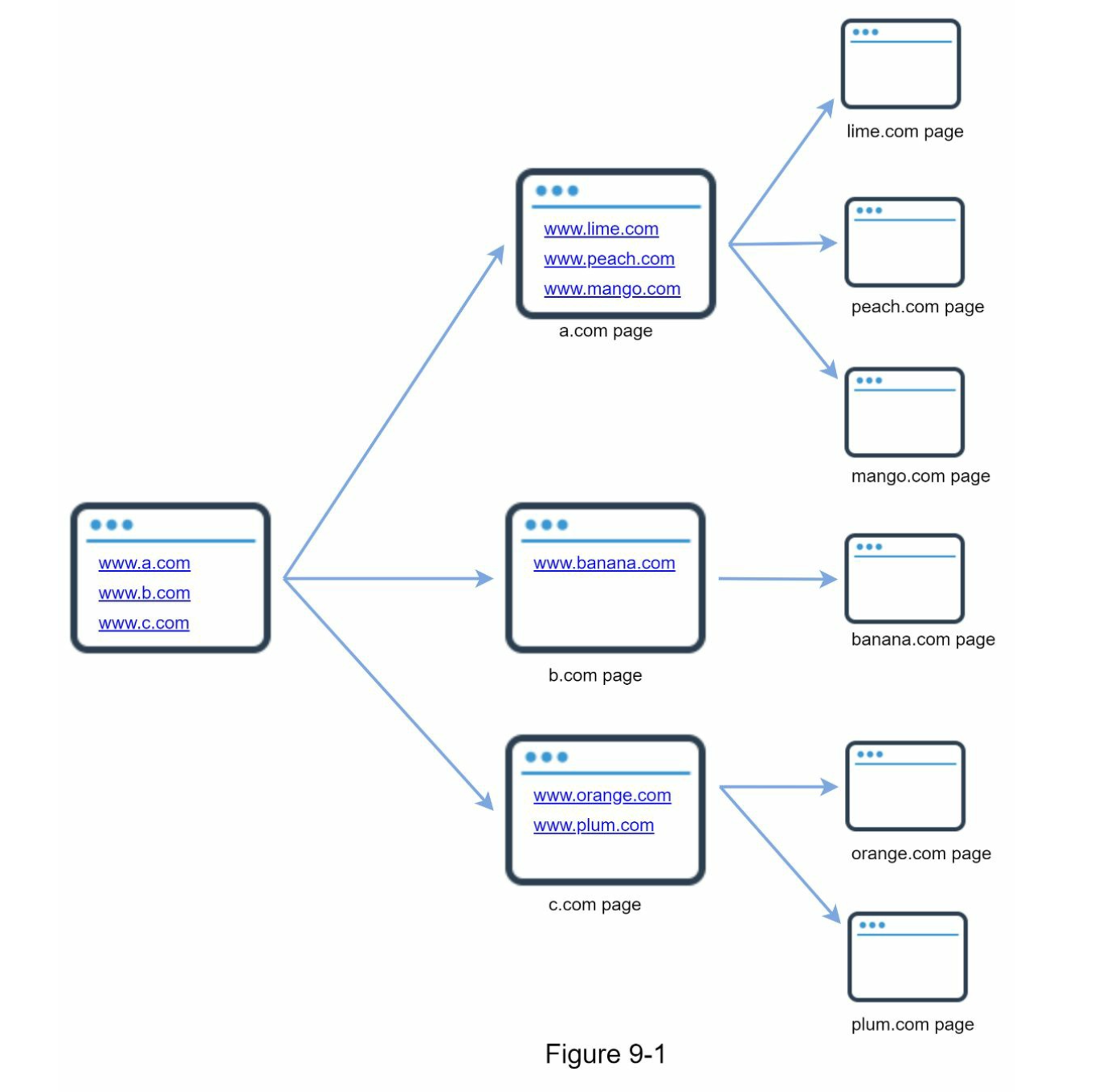
How web crawlers work
Step 1 – Understand problem and establish design scope
Candidate: What is the main purpose of the crawler? Is it used for search engine indexing, data mining, or something else?
Interviewer: Search engine indexing.
Candidate: How many web pages does the web crawler collect per month?
Interviewer: 1 billion pages.
Candidate: What content types are included? HTML only or other content types such as PDFs and images as well?
Interviewer: HTML only.
Candidate: Shall we consider newly added or edited web pages?
Interviewer: Yes, we should consider the newly added or edited web pages.
Candidate: Do we need to store HTML pages crawled from the web? Interviewer: Yes, up to 5 years
Candidate: How do we handle web pages with duplicate content? Interviewer: Pages with duplicate content should be ignored.
Backof envelop estimation
QPS calculation
- QPS = $1,000,000,000 \div \text{30 days} \div \text{24 hours} \div \text{3600} seconds = \text{400 pages per second}$
- Peak QPS = $400 \times 2$ = 800
Storage calculation
Assuming a webpage is around 500kb, we have 1 billion pages = $500 \times 1 \text{billion} = 500 \text{TB per month}$
So for 5 years, we have $\text{500 TB} \times \text{12 months} \times \text{5 years} = \text{30 PB}$
Step 2 – High level design and get buy-in
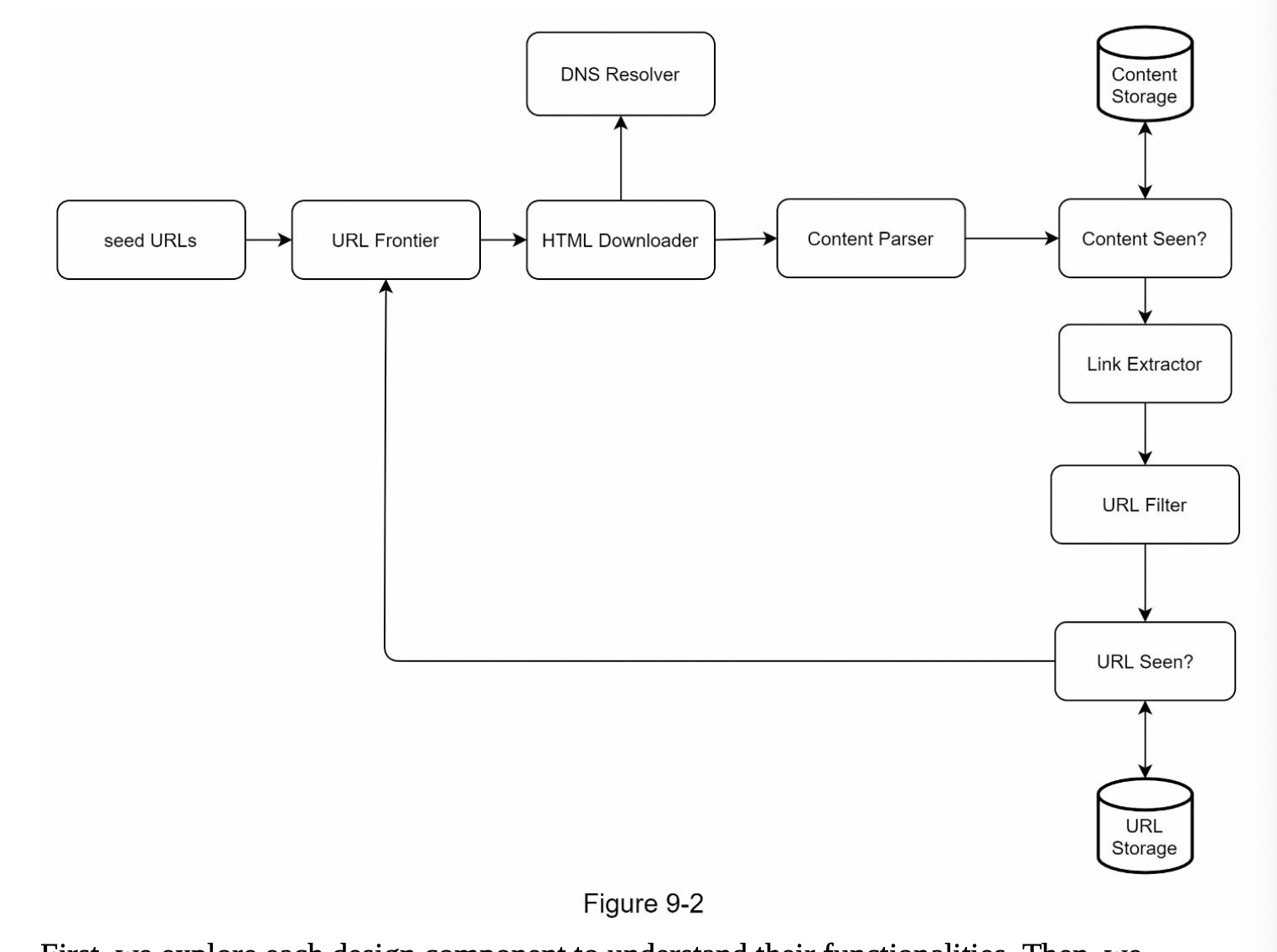
- Seed URLs:
- The intial URL as a starting point. We need to be creative because we want the starting point to contains as many link as possible.
- URL Frontier:
- To store the URLs to be downloaded, will be a FIFO queue
- HTML downloader:
- Download the URL
- DNS Resolver:
- To resolve a domain to an URL. Note that we can also use the public DNS one, however it will create a delay for our crawler to query those.
- As a result, having our own DNS cache server can benefit as sometimes we recrawling from the same website.
- Content parser:
- To validate and parse the website because there could be malformed webpage
- Content seen:
- Double check if the content already exists because it could be the same page but different domain.
- However it's not efficient if we trying to compare the 2 webpage character by character. As a result, we can calculate the hash of the webpage and use Bloom Filter to check if the content is in here
- Content storage:
- For storage, since the content is huge, we can use disk and memory buffer when there is
enqueueordequeueoperation to save space and increase performance. - Note: we only keep popular content in memory to reduce latency
- For storage, since the content is huge, we can use disk and memory buffer when there is
- URL extractor:
- This is to extract the link from a webpage

- This is to extract the link from a webpage
- URL filter:
- Filter the URL if it's in
blacklistedlist
- Filter the URL if it's in
- URL seen:
- Check if we have already seen this URL, which we can use Bloom Filter as well.
- URL storage:
- Stores already visited URLs
Step 3 – Design deep drive
Crawling algorithm
We will do BFS since DFS will be too deep for our search.
URL Frontier
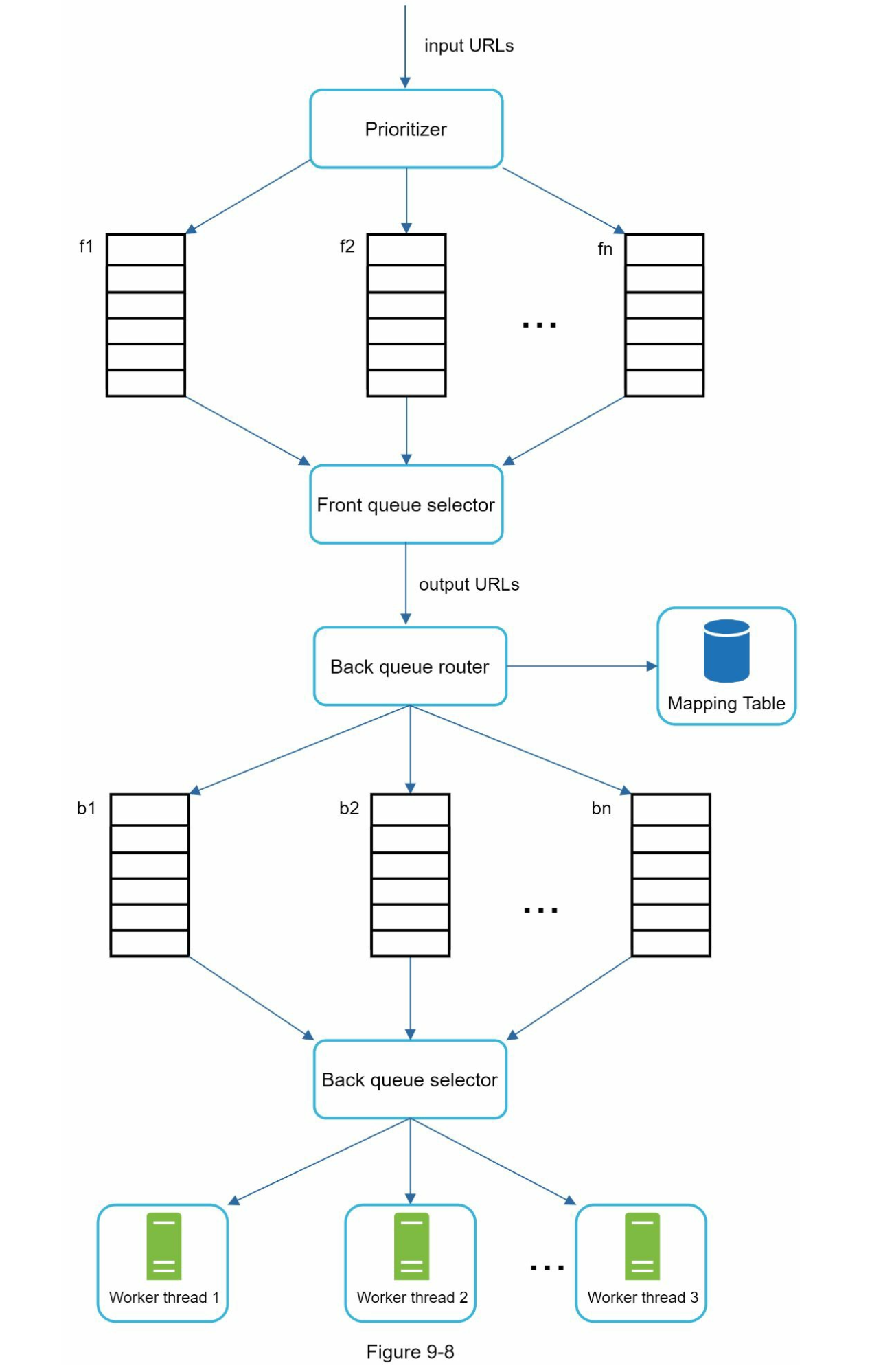
Politeness
We shouldn't send too many requests to the same hosting server within a short period as this would be "impolite" and could considered to be DOS attack.
We can implement a constraint which distribute websites into multiple queue and each downloader thread has a separate FIFO queue to download.
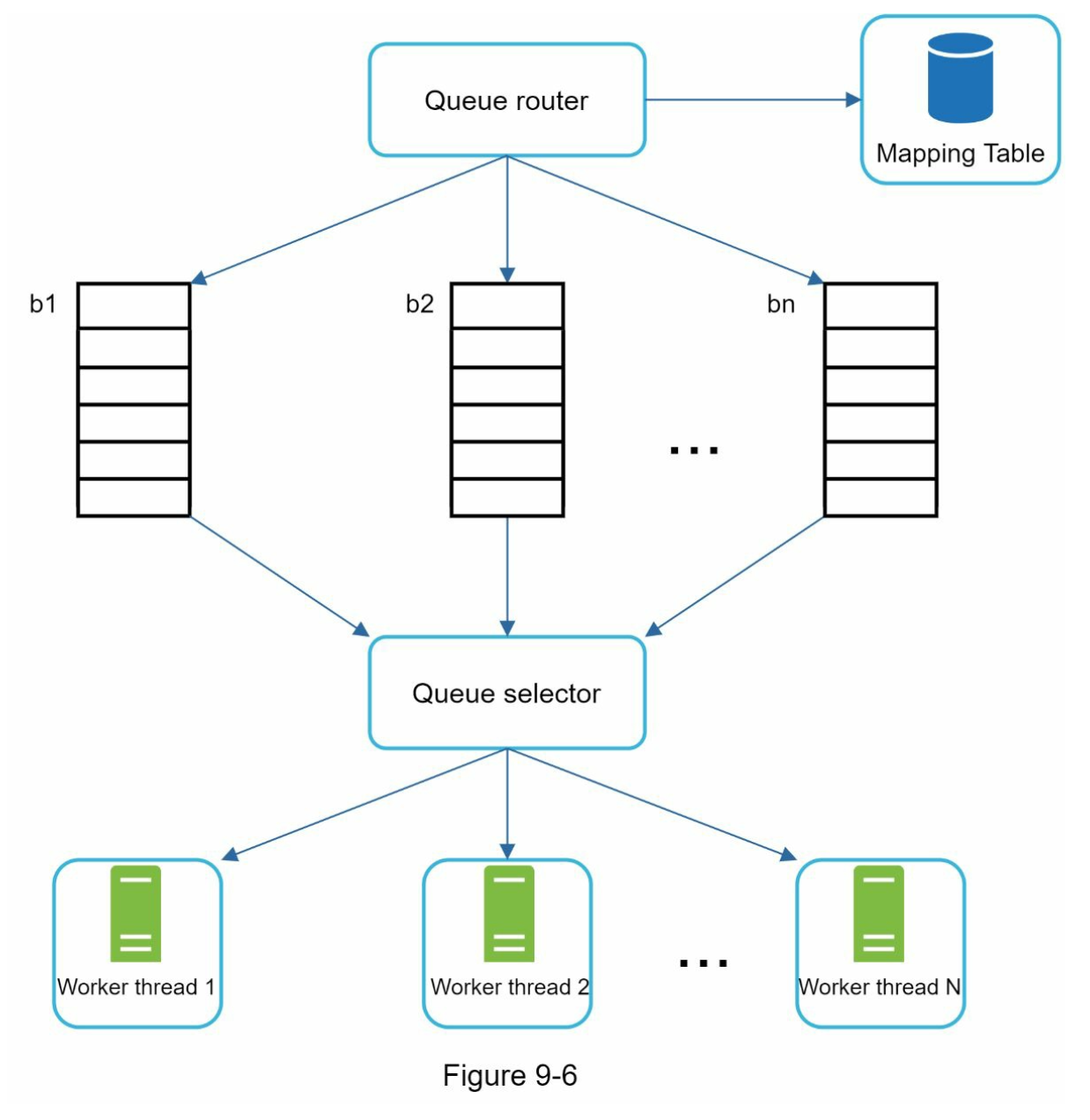
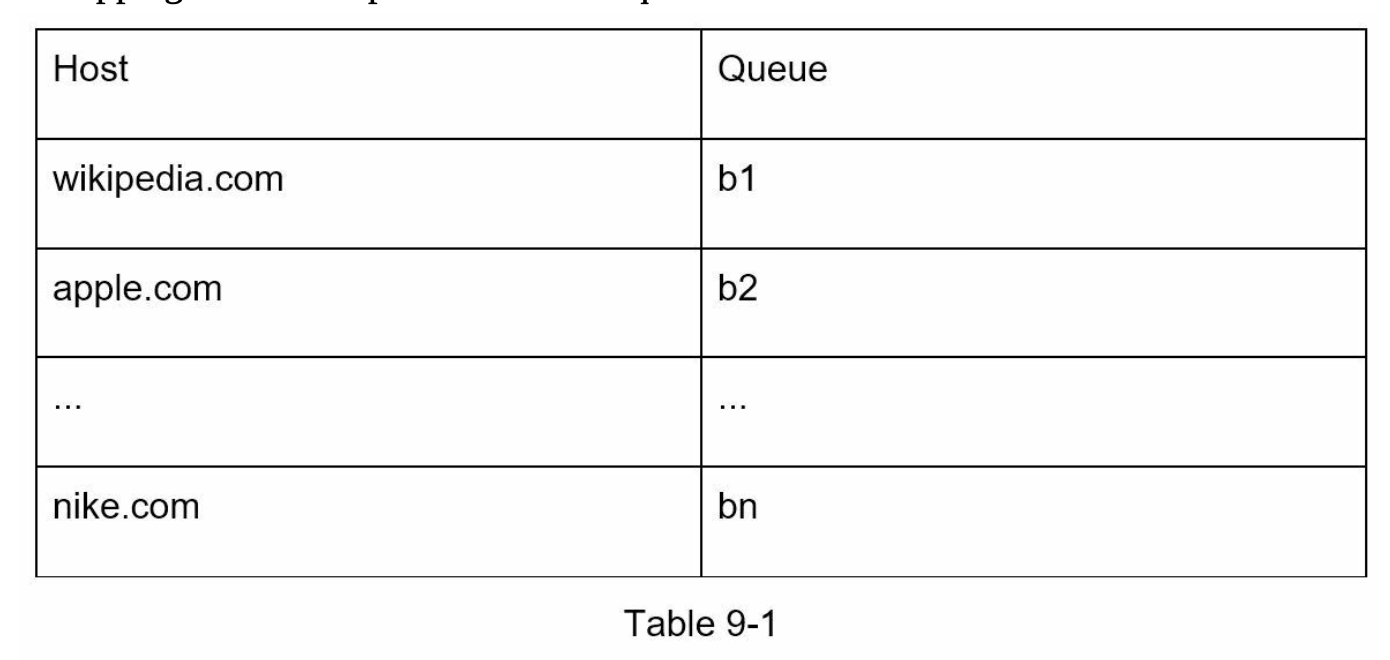
For example, in here, we ensure that each queue (b1, b2, …bn) only contains data from the same host. So we can define something like
- wikipedia.com: queue
b1 - apple.com: queue
b2 - …
This is exactly what the Mapping Table does:
The queueSelector will then select the queue such that it distributes evenly between the worker so the same domain doesn't get flushed
Priority
A random post of discussion about Apple products in a forum should weight less than the Apple homepage itself.
Therefore we need to define a Priority that will handles URL prioritisation. This can be weighted by PageRank for example.
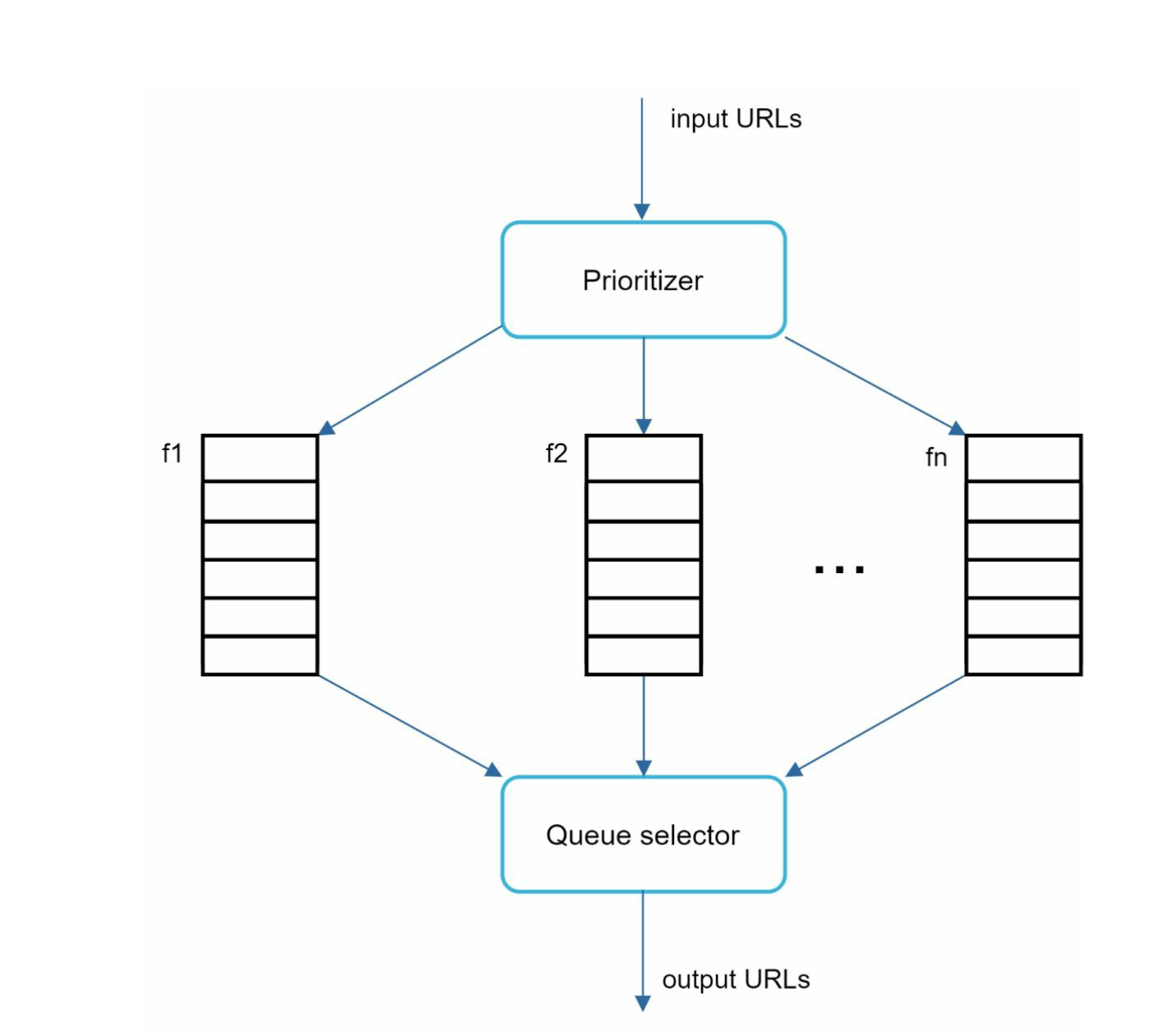
In here, queue f1 to fn will have different priorities, with queue with high priority are selected
The Queue selector will choose a queue with the bias towards the priority.
Combination
In combination of the 2 queues, we have
- Front queue: Prioritizer
- Back queue: Politeness
Update outdated website
We can use a few strategies to re-populate an URL, for example
- Recrawl based on web pages' update history
- Priority URLs and recrawl important pages first
Storage
Putting everything into memory is not a very scalable solution. Because of that we put everything to disk and maintain a memory buffer for enqueue and deque operations.
HTML Downloaders
Parsing robots.txt file
Some websites have robots.txt which specify allows/disallows pages for web crawlers to crawl. We should follow this sites to filter out the list of disallowed URL.
Performance optimisation
There are a few performance optimisation we can do:
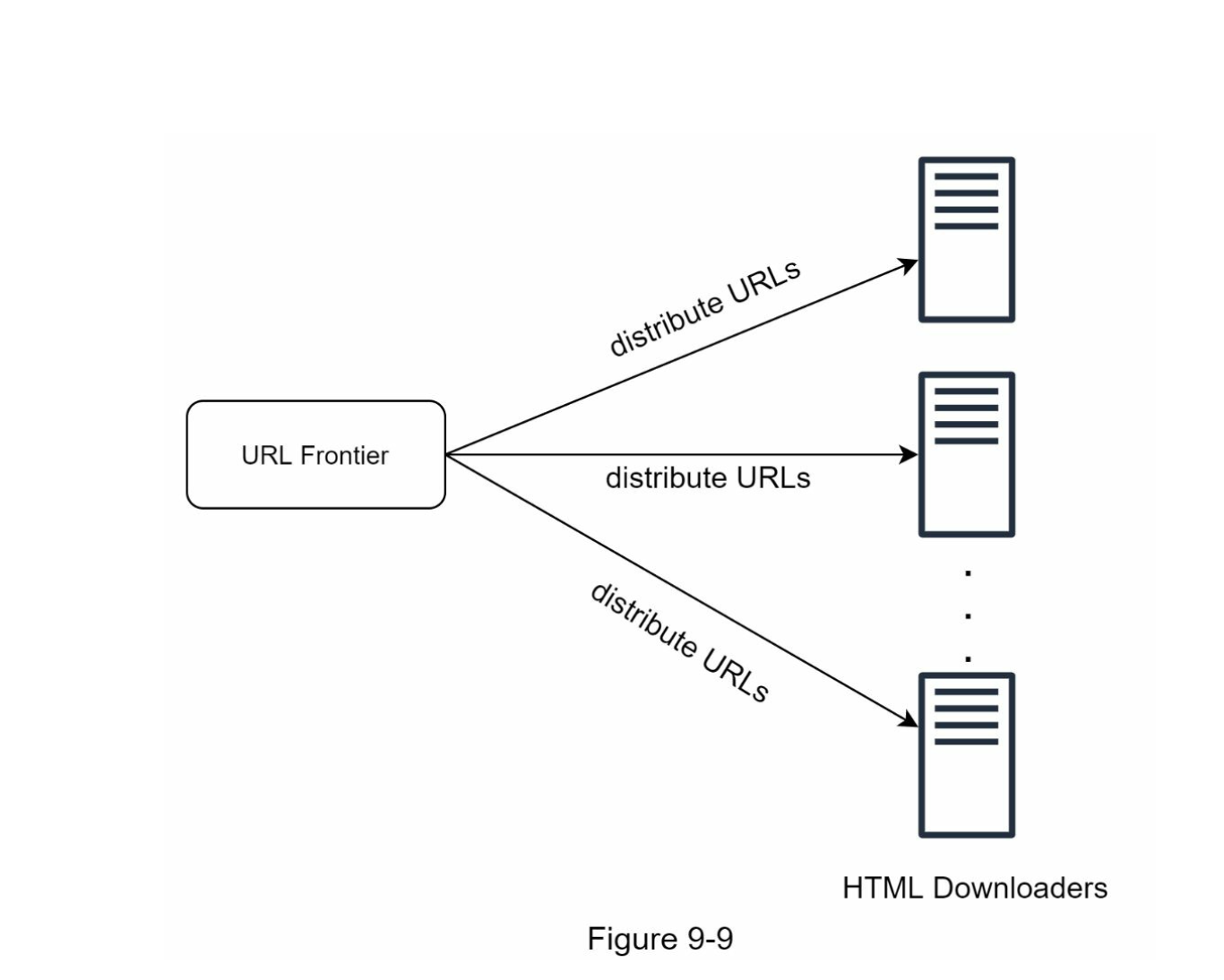
- Distributed crawler:
- Crawl jobs are distributed in multiple servers, each servers run multiple threads.
- Cache DNS resolver
- Locality
- Deploy the crawlers geographically. Crawlers will be faster to crawl the website if it's closer to host.
- Short timeout
- Sometimes websites are not responsive. To avoid this, crawlers can stop after a period of time and start crawling other pages
Robustness
Since it's a worker, we can consider
- Design Consistent Hashing
- Save crawl states and data
- Fanout Pattern
- Exception handling
- Data validation
Extensibility
If we want to support more format, or any extension, we can include here:
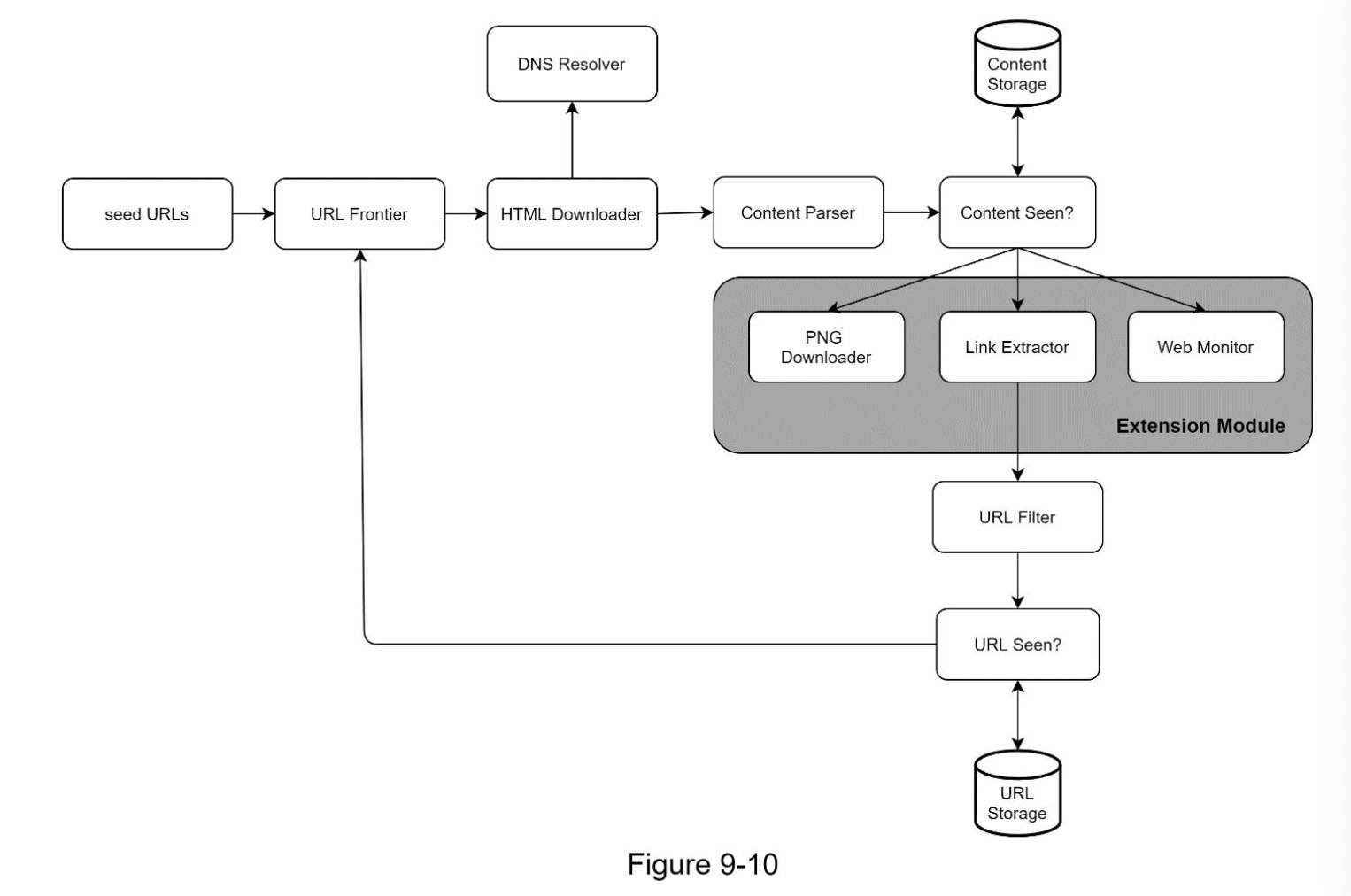
In here the:
- PNG downloader: to download PNG files
- Web monitor: monitor the web and prevent copyright and trade mark
Detect and avoid problematic content
We can try to dtect and avoid
- Redundant content:
- Some websites have the same content and we want to filter it out using Hashses or checksums
- Spider traps
- Spider traps will cause the crawler to have infinite loop, for example:
www.spidertrapexample.com/foo/bar/foo/bar/foo/bar/... - We can avoid this by setting the maximum length for an URLs or apply an URL filters. There is no 1 size fit all for the spider trap
- Spider traps will cause the crawler to have infinite loop, for example:
- Data noise
- Ads, spam urls, code snippets are not useful and exclude if possible
Step 4 – Wrap up
If have time we can mention:
- Serverside rendering:
- Most of the websites nowadays are using javascript library that render the UI graphics on the flight. To solve this problem, we can perform serverside rendering
- Filterout unwanted page.
- Since we have a finite storage capacity
- Database replication and sharding
- If we're using database to store our URLs or site content, we can perform Database/Database scaling techniques.
- Horizontal scaling:
- We can perform horizontal scaling for the crawlers to perform multiple tasks.
- The key is to keep the servers stateless
- Availabilty, Consistency and Reliability
- Analytics for fine-tuning