Design Unique ID Generator In Distributed System
Question
You are asked to design a unique ID generator in distributed systems. Your first thought might be to use a primary key with the auto_increment attribute in a traditional database.
However, auto_increment does not work in a distributed environment because a single database server is not large enough and generating unique IDs across multiple databases with minimal delay is challenging.
We're going to follow the steps in System Design Framework
Step 1. Establish design scope
Candidate: What are the characteristics of unique IDs?
Interviewer: IDs must be unique and sortable.
Candidate: For each new record, does ID increment by 1?
Interviewer: The ID increments by time but not necessarily only increments by 1. IDs created in the evening are larger than those created in the morning on the same day.
Candidate: Do IDs only contain numerical values?
Interviewer: Yes, that is correct.
Candidate: What is the ID length requirement?
Interviewer: IDs should fit into 64-bit.
Candidate: What is the scale of the system?
Interviewer: The system should be able to generate 10,000 IDs per second.
As a result we have the following requirements:
- IDs must be unique
- IDs is numerical values only
- IDs fits into 64 bit
- IDs are ordered by date
- Ability to generate over 10,000 per second
Step 2. Propose a high-level design and get buy-in
We can consider some of the options here and list out the pros and cons of each:
- Multi-master replication ID generator
- Universally unique identifer (UUID)
- Ticket Server
- Twitter snowflake ID generator
As a result, Twitter snowflake ID generator fits our requirement the most
Step 3. Design deep dive
So Twitter snowflake ID generator has the following design

Timestamp bit
Timestamp bit is the most important bit because as timestmap grow with time — IDs are sorted by time
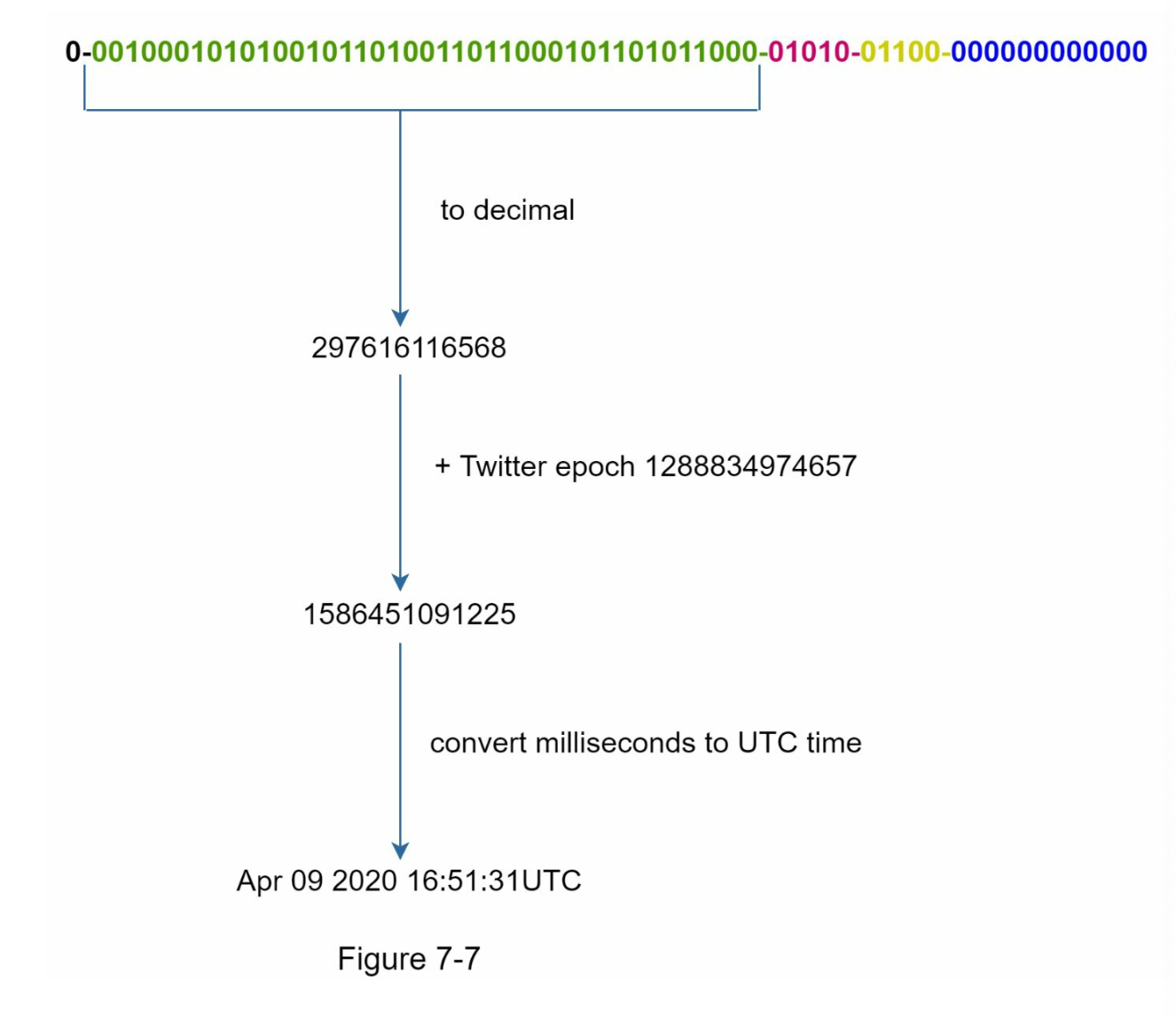
We can also convert to UTC back and fort. Note that the maximum timestamp that can be represented in 41 bits is
$$2^{41} - 1 = 2199023255551 \text{ms} = \text{69 years}$$
So after 69 years we need to adapt some technique to migrate the IDs
Sequence bit
Since the sequence bit as 12 bits, we have $2^{12} = 4096$ combination. So that means we can generate 4096 new ID per millisecond
Step 4 - Wrap up
If there is extra time, we can discuss:
- Clock synchronisation:
- We assume that our generation id servers runs in the same clock but it's not
truewhen the server is running in multicore — a Clock drift might happens that lead to 1 of the core has different time to another core - As for solution, we can implement Network Time Protocol (NTP) to synchronise the time
- We assume that our generation id servers runs in the same clock but it's not
- Section length tunning
- In a very low concurrency system, we might need more time bit to keep track of the extra nano seconds. As a result, we can increase the Timestamp bit and Truncate the sequence bit
- High availability:
- Since the system is critical, it needs to be highly available.
- We can scale between different regions and so on with replications to achieve this.