Design Key-Value Store
Single server key-value store
For single server, we can simply use a hashmap to store the key, value.
For optimisation we can do:
- Data compression
- Store frequent used data in memory and the rest on disk
Distributed server key-value store
Consideration
CAP theorem needed to be considered in which case we need to decide between:
- CP (consistentcy + partition network tolerance): Support consistency and sacrifices availability
- For this we want our communication to be Transactional
- AP (avialablity + partition network tolerance): Support availbility and sacrifices consistency
Data partition
Problem
Since it's not possible to fit everything into a single server so we need to distribute data in the way that's:
- Evenly
- Minimise data movement when it's modified
Solution
Using Consistent Hashing, we can evenly distribute our data to relevant server and minimise data movement. Which is good for ^952639
- Automatic scaling: servers could be added and removed automatically depending on the load.
- Heterogeneity: number of nodes is propotional to server capacity. Server with higher capacity will have more virtual nodes.
Data replication
Replication is important to achieve availability and reliability. We choose the first $N$ server next to the ring from Consistent Hasing to replicate the data.
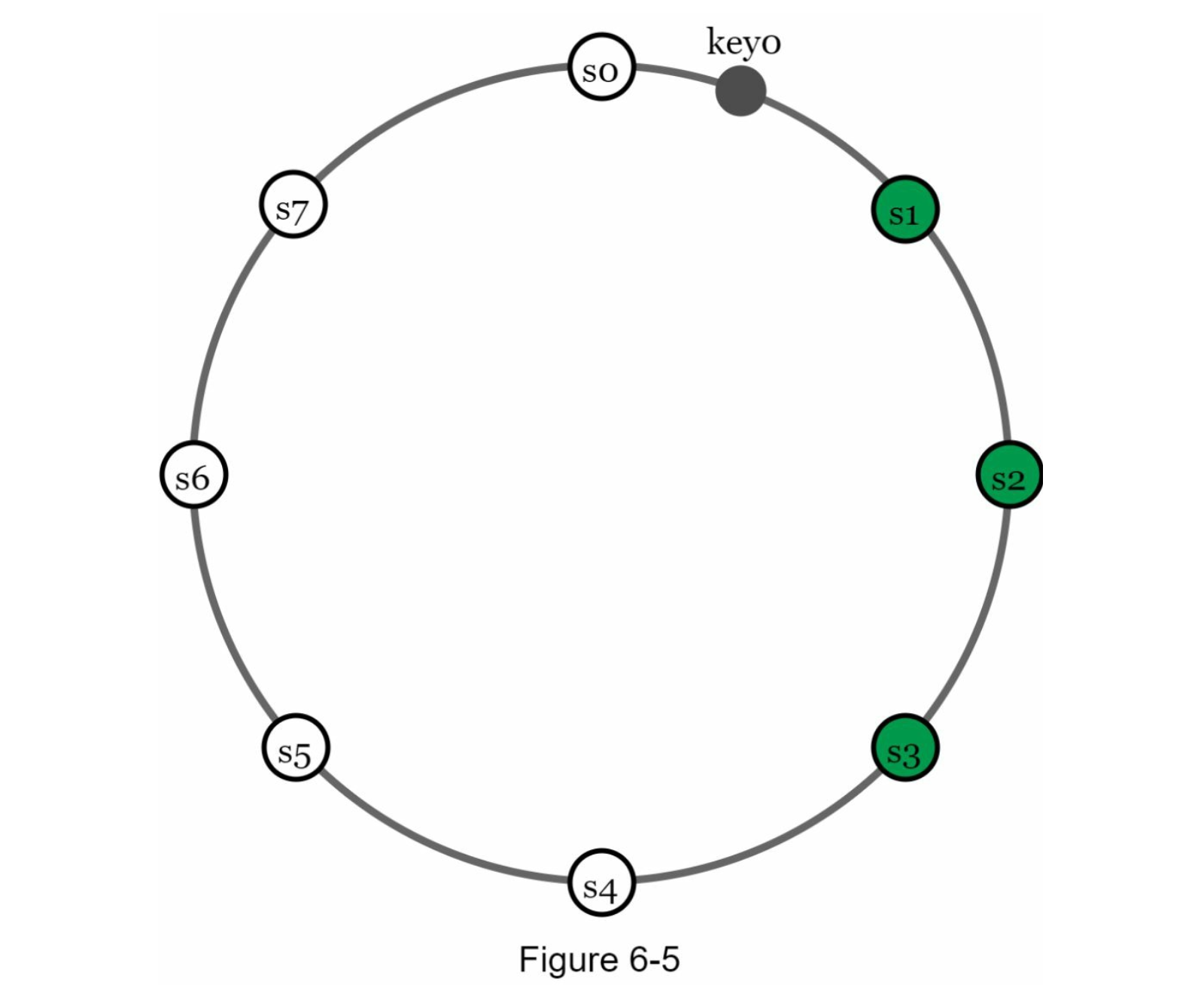
For example in here we replicate key0 with $N = 3$
Note: These $N$ server are actual physical servers not virtual nodes. This is guarantee that the data is spread uniquely amongst those server.
For more reliability, replicas are placed at different data centers for disaster recovery.
Data Consistency, Synchronisation
Using the concept of Consensus and Quorum. We can synchronise a data by having a fixed number of nodes agree that a data is valid
Quorum consistency
So if we have
- $N$: number of node in total
- $W$: minimum number of node needs to be acknowledged for write
- $R$: minimum number of node needs to be acknowledeged for read
For example in the system which $N = 3$ we have this following diagram.
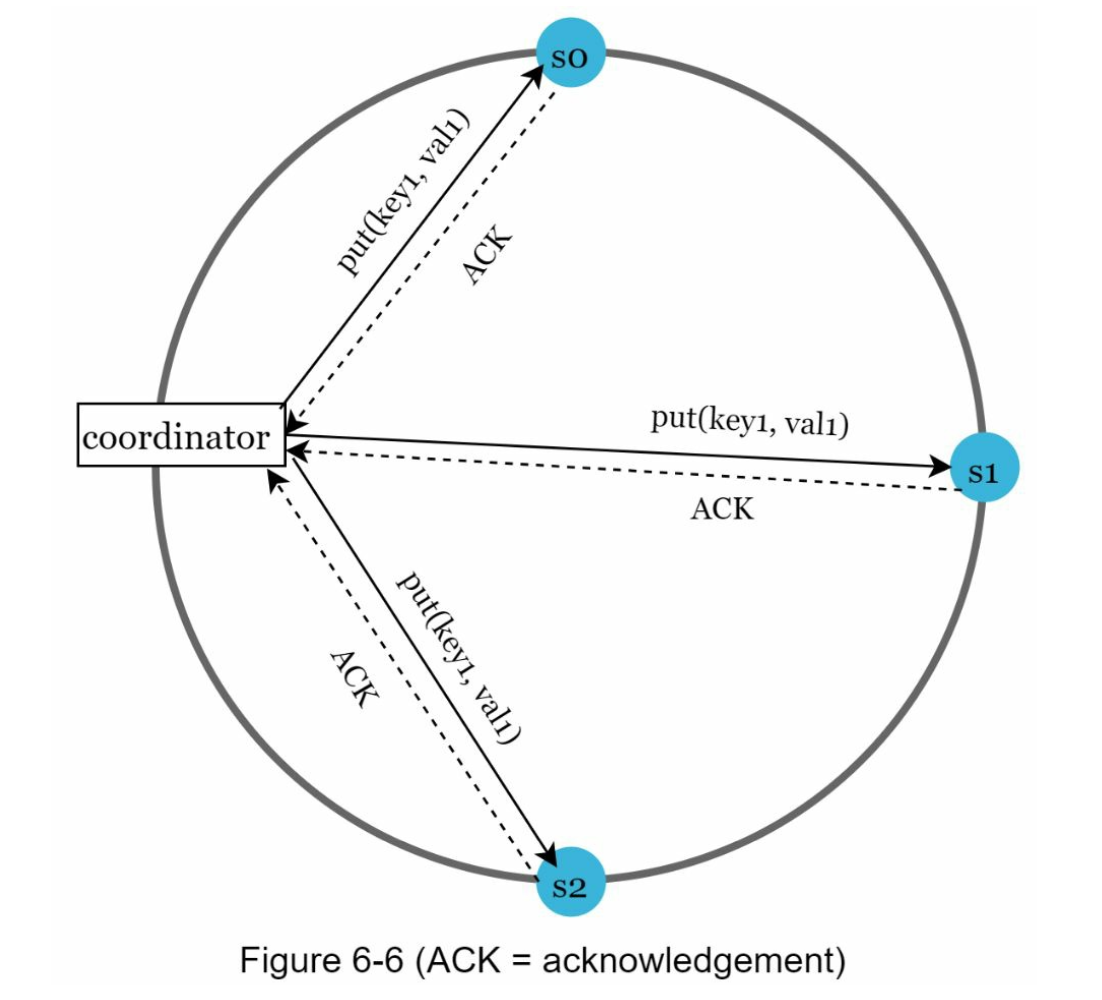
We have the following condition:
- $W + R \gt N$: Strong consistency
- Because in the case where 1 node is either $W$ or $R$. We have $W$ + $R$ $=$ $N$.
- However, when $W + R > N$ that means 1 node is acknowledger for both read and write.
- Therefore that node always have latest data.
- Therefore strong consistency.
- $W + R \leq N$: Strong consistency not guaranteed
- There possibly exists a node that is not acknowledger for both read and write
So how do we distribute the node? Consider the case that we want strong consistency (i.e $W + R > N$)
- Fast write is important
- We can set $W = 1$ and $R = N$:
- We write very fast, since there is only 1 node that need to acknowledge to make sure the write register.
- After the write, the system needs to synchronise to $N$ node in the background
- However, to make sure the data we read is consistent, we need to read the whole $N$ nodes. This would guarantee that we have the latest data
- As a result, read is very slow
- Fast read is important
- We can set $R = 1$ and $W = N$.
- We read very fast, we just pick a random node to read.
- Trade of is our write is very slow, in order to read from any node, the system needs to sync the data to every $N$ node
How does it work in the background
For example:
- everytime you read you're gonna read from $R$ nodes
- everytime you write, you write to $W$ nodes
- in a system that $W + R > N$, it's mathematically impossible to not read or write to the overlap node
Let imagine a 3 node scenarios:
- Node A:
{"user_id": 1, "balance": 100, "version": 5} - Node B:
{"user_id": 1, "balance": 100, "version": 5} - Node C:
{"user_id": 1, "balance": 100, "version": 5}
Let's choose $W + R > N$, $W = 2$, $R = 2$
- Write
balance = 120, choose 2 random node since $W = 2$- Node B:
{"user_id": 1, "balance": 120, "version": 6} - Node C:
{"user_id": 1, "balance": 120, "version": 6}
- Node B:
- Now the data is
- Node A:
{"user_id": 1, "balance": 100, "version": 5} - Node B:
{"user_id": 1, "balance": 120, "version": 6} - Node C:
{"user_id": 1, "balance": 120, "version": 6}
- Node A:
- Try to read the latest balance, with $R = 2$. It's impossible to have a combination of A,B or C that would not return a version 6
- If you read from A and B, B has higher version. The coordinator will resolve it and return latest version with
balance = 120- It realise that
NodeAis out of date and update the data toNodeAtoversion: 6. See: Anti Entropy > Passive anti-entropy
- It realise that
- If you read from node C and A, similar thing happen
- If you read from B and C, of course you have the latest version
- If you read from A and B, B has higher version. The coordinator will resolve it and return latest version with
Decide the consistency modal
- Strong consistency: Always most up to date version
- Weak consistency: value is not always most up to date
- Eventually consistency:
- Another form of weak consistency
- Given enough time, all updates are propagated and replicas are consistent. The same concept in BASE
- To achieve this, $W + R \leq N$, a single READ might achieve stale data but very fast.
- Use cases: Social medias feed, view counts, etc
- Eventually consistency:
Inconsistency resolution
For example when the 2 clients all put different data to our key/value store the same time, this could create conflicts between 2 servers.
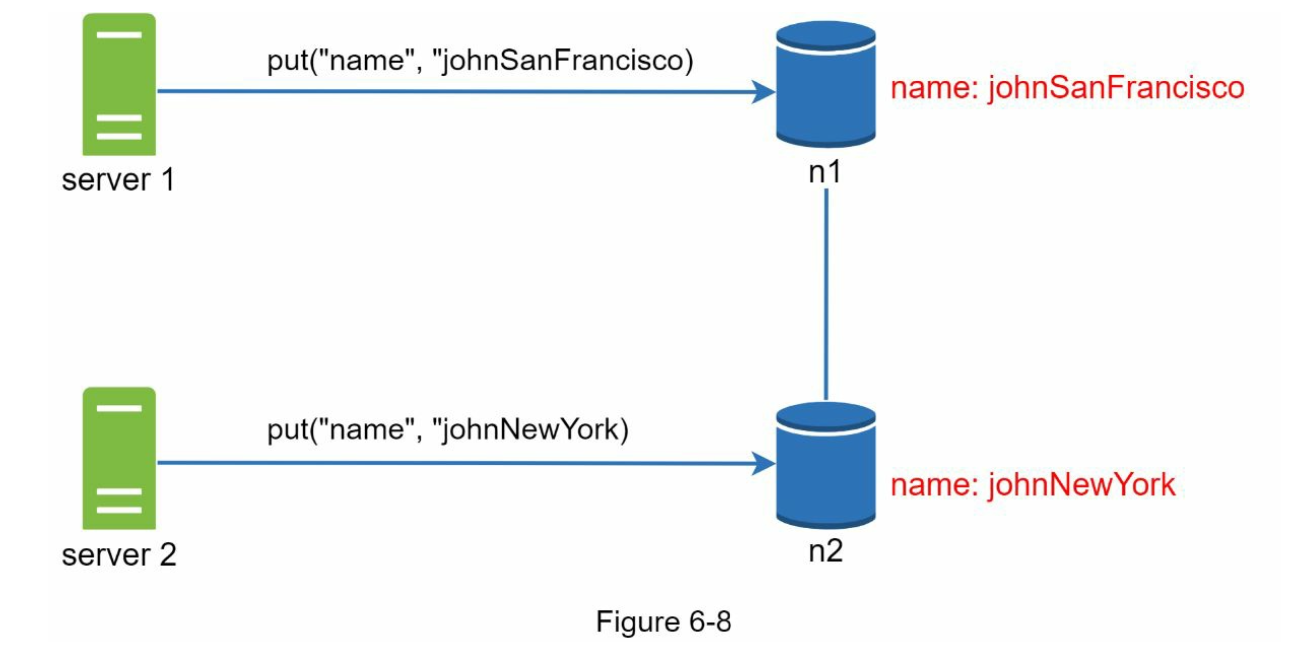
In this case, we can use a Vector Clock to detect where there is a conflict and then code our client to resolve the conflict. Vector clock not only work with write, it's also for read as well
Error handling
Failure detection
We can use Gossip Protocol to detect if 1 node is down. It's not enough to conclude that 1 node is down because another node say so. We need to have a number of node confirm the same time.
Instead of All-to-all multicasting, Gossip Protocol is more efficient in the case we have many servers in our system.
Handling failure
After detected a failure we need to detect if it's a
- Temporary error
- For temporary failure, we can use Sloppy Quorum to make sure that all the write and read are still serve even though a node is offline.
- When a node is down, another node will process the request of the down node temporary and hand the job back when that process is available (Hinted Handoff)
- Permanent error
- For permanent error, we can use Anti Entropy protocol for synchronisation with stale nodes. This is a very helpful technique when we have a replica that potentially have the same information of unavailable node. Which then we can use Anti Entropy to synchronise over with our replica
- Server outage error
- For server outage error, we make sure that our servers are distributed across multiple data centers.
Design key-value store
Because the system is distributed, there must be a coordinator acts as a entry point for the client to talk to.
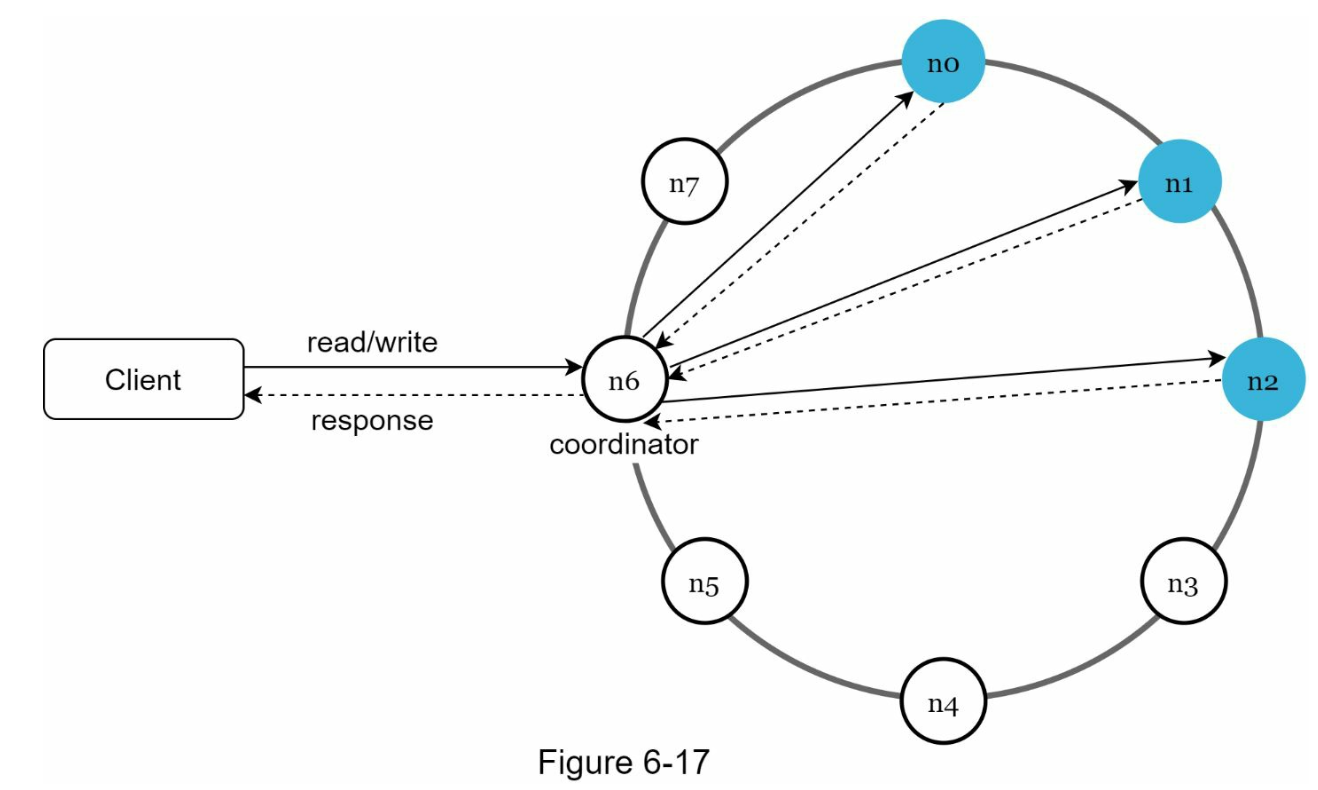
- Clients communicate with key-store value via a coordinator from APIs:
get(key)andput(key, value)- Coordinator node will take request from client and give it to the corresponding node.
- Nodes are distributed using Consistent Hashing as discussed in data partition^952639|.
- Because of the natural of consistent hashing, adding and removing a node doesn't need us to do any manual adjusting.
- Data is then replicated at multiple node
- There is no single point of failure because every node shares the same responsibility:
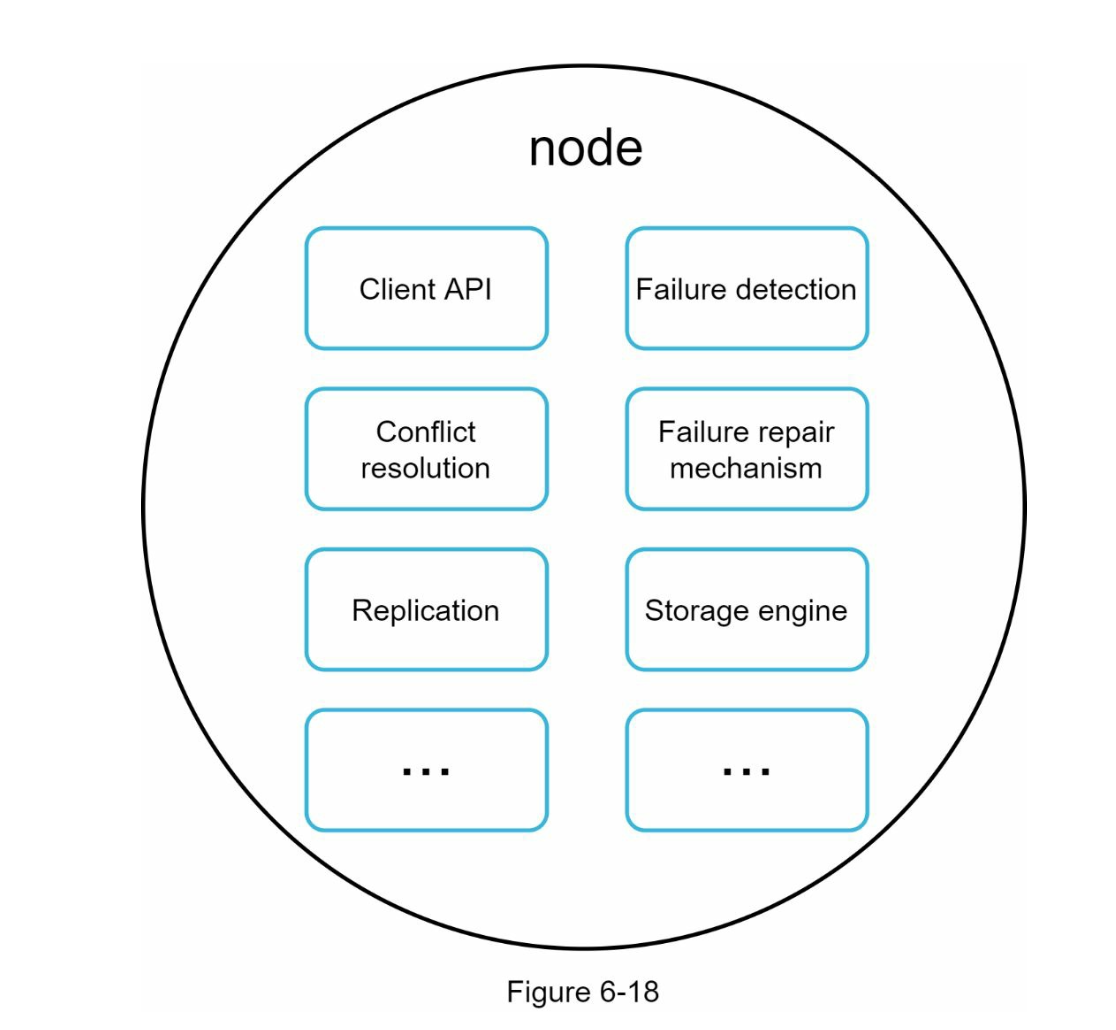
When node handle write request
Note that the example follow based on the architecture of Cassandra.
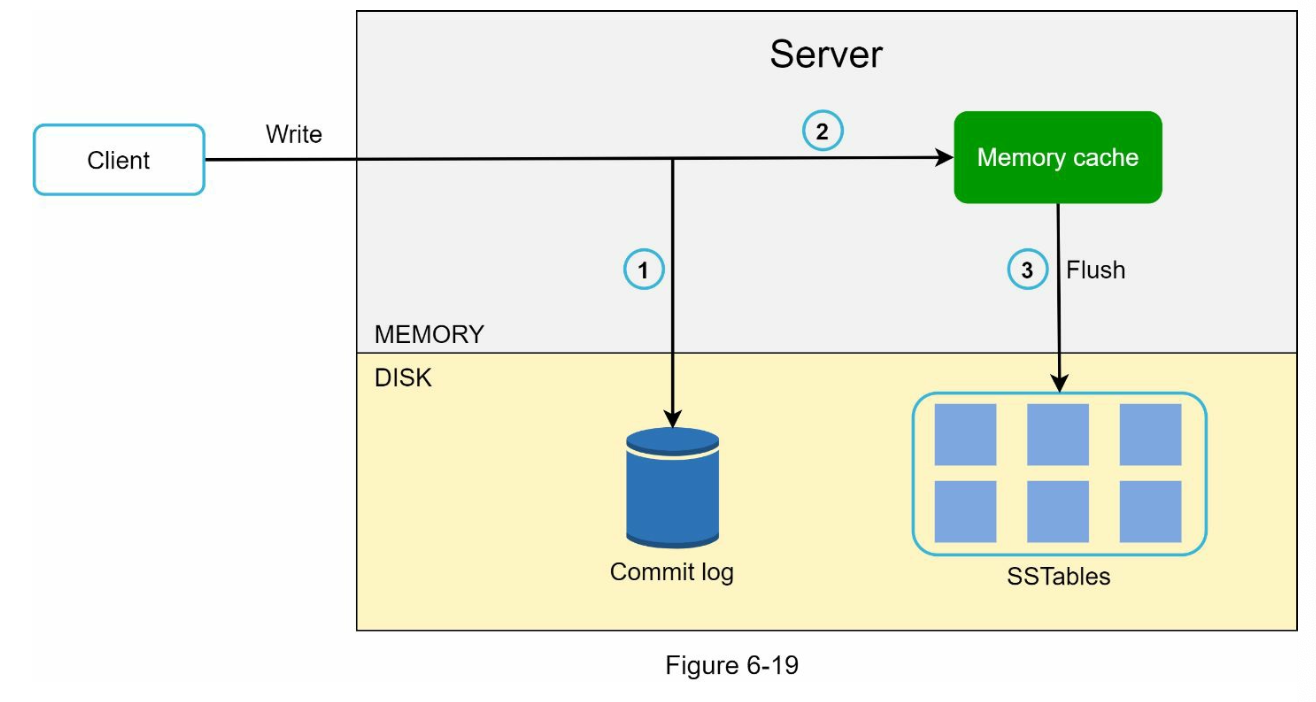
When the node receives the write from client:
- The write request will go to a commit log file
- This file is to store the changes of the data. It helps to ensure data recoverability in case of failure
- Data is then save to a memory cache
- When the data is full or reaches a predefined threshold, data is flushed to SSTable.
- The use of SSTable here is because it performs sequential writes, which is much faster to traditional databases like B Tree and B+ Tree which uses a lot of random I/O
- Since the data is sorted, we can perform Binary Search to quickly find data.
When node handle read request
- It checks if the data is in memory cache. If so it will return result
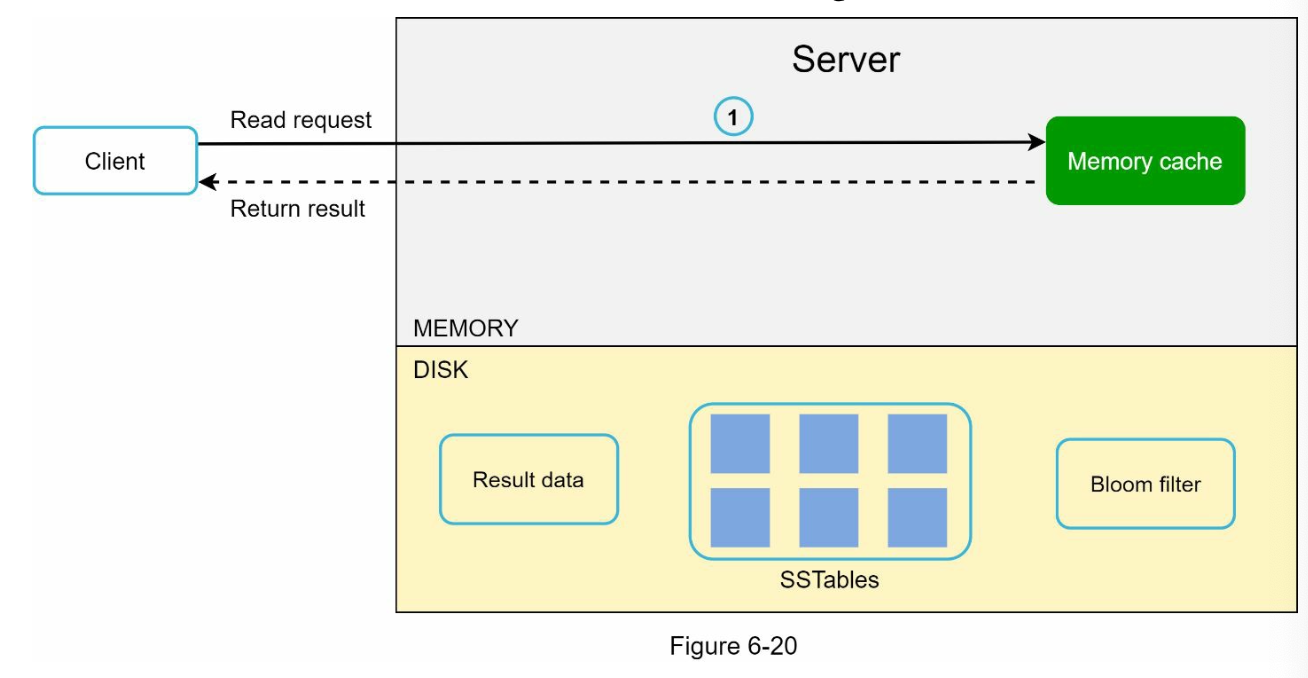
- If it's not in memory, we will find the data in the SSTable contains the key.
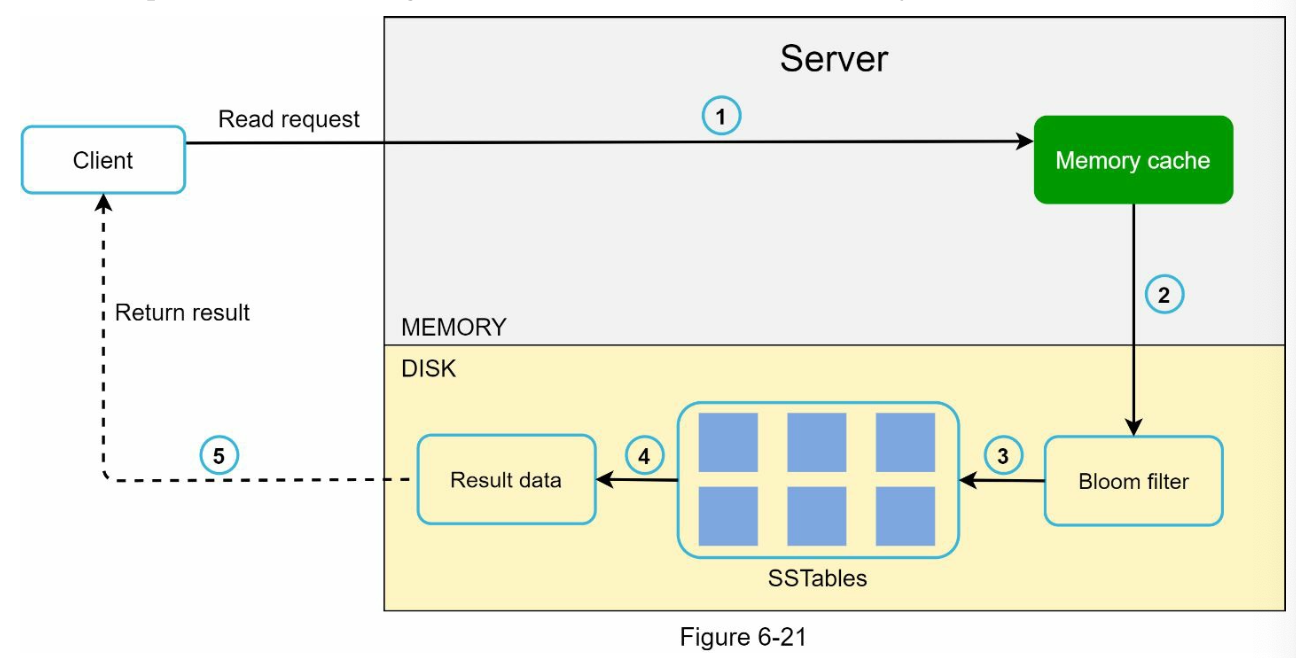
- In here we use Bloom Filter to determine helps us to find out which table holds the data
- SSTable will will return the result
- The result will be passed back to the client