Database Sharding
There are multiple type of sharding, we need to consider doing the easy one first before continue with the hard one. The following order will be from easy to hard.
1. Vertical sharding
A table could be split to smaller table. For example:
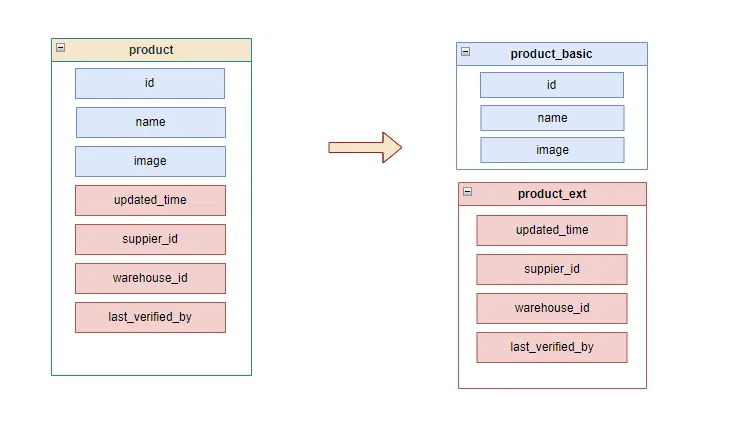
In this example, we have defined 2 group of fields:
- In frequently changes (blue)
- Frequently changes (red)
If the red fields in here are updated more frequent, we can split that table out to one in-frequently table and one fre0quently table.
Pros:
- reduce the potential lock for querying on the
product_basictable
Cons:
- Table size still increasing
- To address this problem, we can consider cold storage for archiving
2. Table partitioning
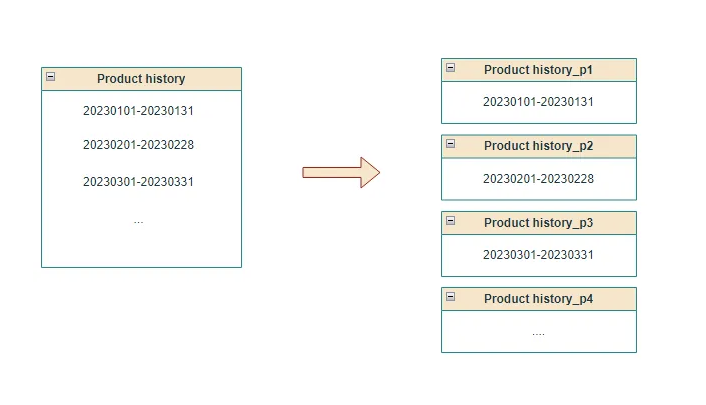
One table can create multiple partition for example:
CREATE TABLE sales (
sale_id serial PRIMARY KEY,
sale_date date,
amount numeric
);
CREATE TABLE sales_january PARTITION OF sales
FOR VALUES FROM ('2023-01-01') TO ('2023-01-31');
CREATE TABLE sales_february PARTITION OF sales
FOR VALUES FROM ('2023-02-01') TO ('2023-02-28');
As a result, the data will be stored in the partition table. The main table will only be fore the schema and so on.
If you want each table in different location. You can create a table space:
CREATE TABLESPACE my_tablespace LOCATION '/path/to/disk1';
CREATE TABLE sales_january PARTITION OF sales
FOR VALUES FROM ('2023-01-01') TO ('2023-01-31')
TABLESPACE my_tablespace;
Pros:
- Reduce the table size and potentially can store the table across different disk
Cons:
- Still one machine serving the database hence bottle neck at the machine level
3. Range based sharding
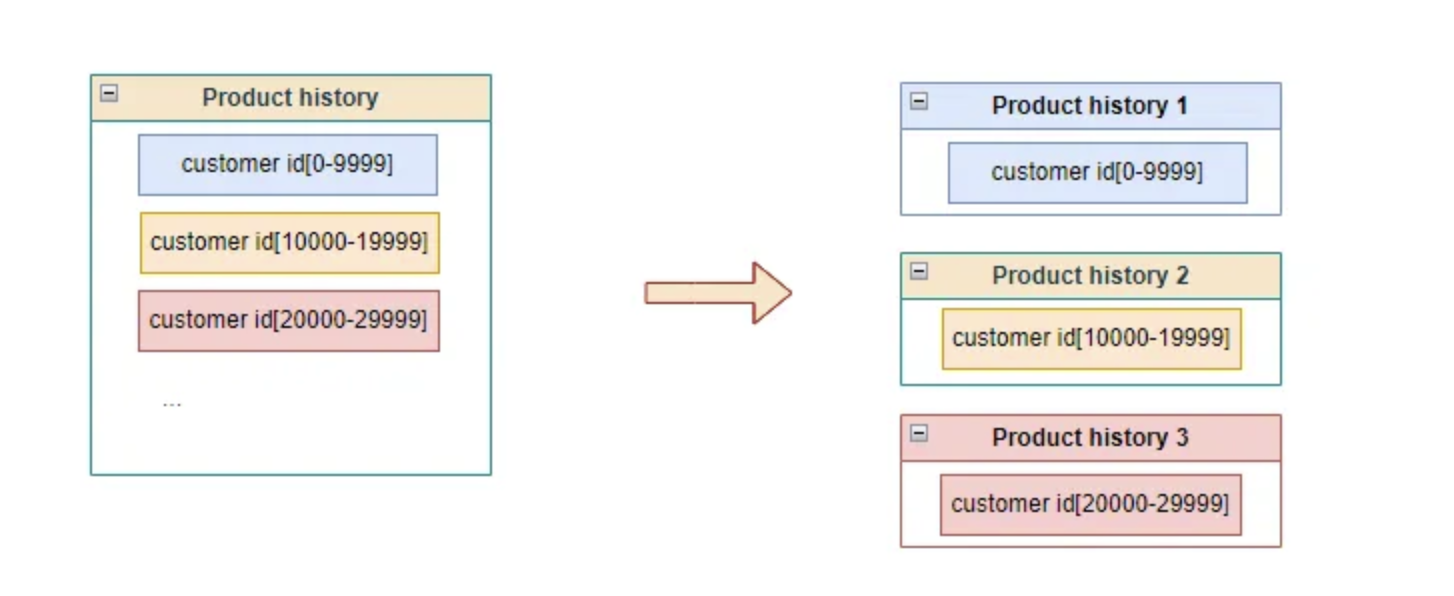
In here we can shard our table based on range. The sharded table can be located in different machine.
If one machine has a problem, it only affect a particular customer.
You can also choose to shard between different range, for example customer_id, user_id, location_id or so on.
Pros:
- Reduce table size
- Split the table to different machines, hence off load from one machine
- Can still use incremental id as the primary key
Cons:
- hotspot — for example if we choose to shard our data based on the key
location_id, if everyone stays in the same place then it will create a hotspot.
4. Key-based sharding
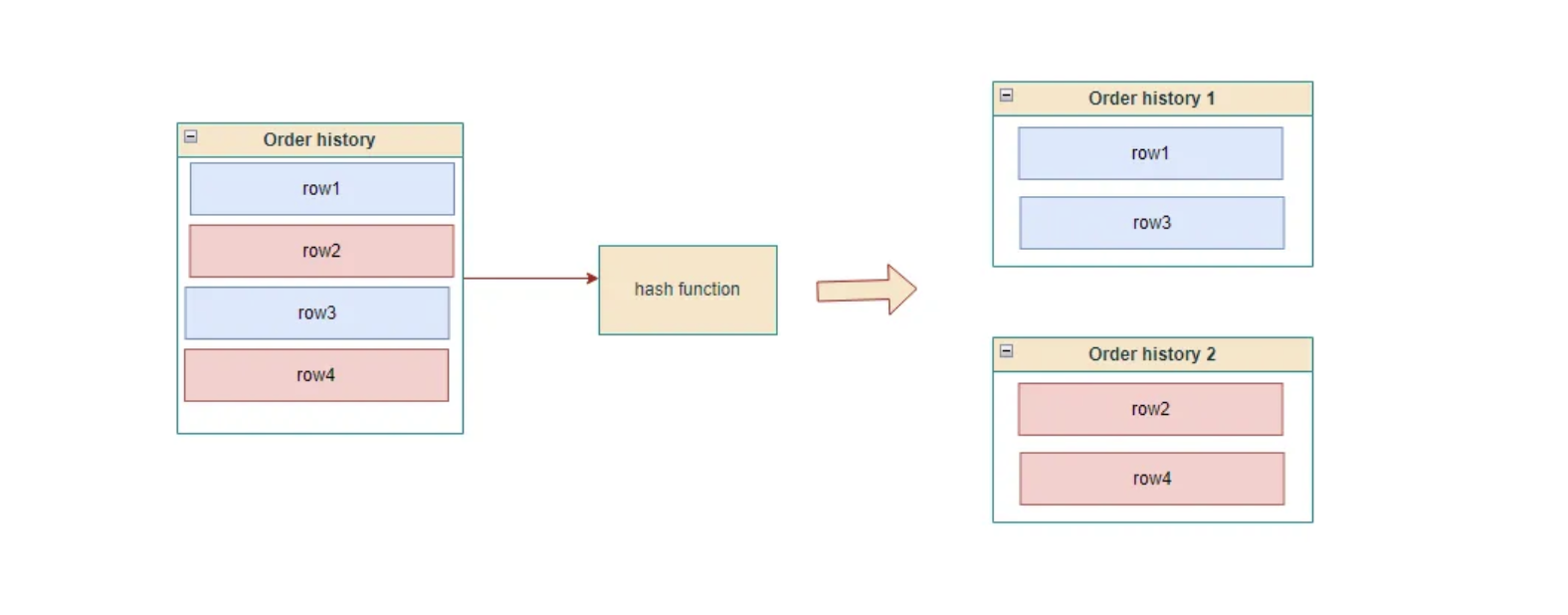
In here we have to use a hash function. The hashfunction has to be unique enough so that it distribute to different shard equally. We can use Consistent Hashing concept
Pros:
- Reduce table size
- Off load from one machine
- Avoid hotspot
Cons:
- Complex to tune the hash function
- Cannot use incremental id
- No subquery, no joins
- Transaction is hard to control — Consider Saga architecture pattern or Two Phase Commit
- Need to involve middle engine such as which dependent on them
As a result, maybt this is more suitable for NoSQL, for Database/SQL is very complicated and has drawback.