Cassandra
Cassandra is a wide column NoSQL database where data is distributed as rows.
It basically looks like regular RDBS however when storing in the system.
For example a table would look like following:
ID Last First Bonus
1 Doe John 8000
2 Smith Jane 4000
3 Beck Sam 1000
It will be a bit differently, for example:
{ row1: { "ID":1, "Last":"Doe", "First":"John", "Bonus":8000}, row2: { "ID":2, "Last":"Smith", "Jane":"John", "Bonus":4000} ... }
For example a table would look like this:
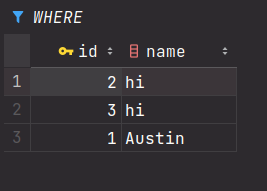
Similarity to SQL
Perform querying
To perform querying or inserting in Cassandra, they use Cassandra Querying Language (CQL) which looks similar to SQL:
For example
insert into "Customers" (id, name) VALUES (3, 'hi');
However you cannot do join query
Database schema
In Cassandra, we can have database schema. For example to create a table we can do the following:
create table "Customers"
(
id bigint primary key,
name text
);
Difference between Cassandra and SQL
Although it looks the same as SQL, functionality wise it's not the same. For example, in Cassandra, you can overwrite the same primary key.
For example in your database if you have record id: 1, name: Austin with 1 is a primary key and you perform an insert:
insert into "Customers" (id, name) VALUES (1, 'hi');
It will overwrite the value of Austin to hi. SQL however prevents us to do this.
[!note]
The reason for this is because if we want to have uniqueness check, Cassandra will have to do a read for each write, therefore will affect the performance of the query. Doing like this make write very efficient.
Lightweight transaction
To prevent the above, Cassandra introduces a concept of lightweight transaction.
So for the query above, we can do something like
insert into "Customers" (id, name) VALUES (1, 'hi') if not exists;