Map-Reduce
Is a technique that has two tasks:
- Map tasks (Splits & Mapping)
- Reduce tasks (Shuffling, reducing)
For example given an input where we need to get the frequency count of each word:
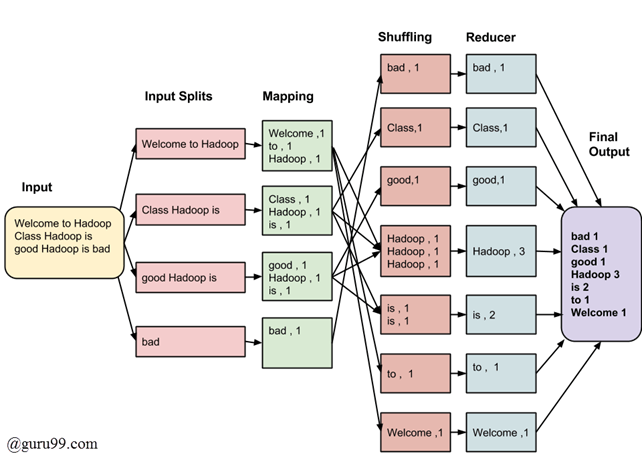
- First, the
mappingwill map the frequency of each word in the input splits. - Shuffling will then sort the word so that it's easier for the reducer to aggregate the data.
- Reducer simply aggregate all the data to the final output
Hadoop is an open source framework for map-reduce