Design Rate Limiter
Why we use rate limiting for API?
- Prevent DDOS
- Reduce cost
- Prevent server overloading
Step by step to design a rate limiter
Step 1. Establish design scope
- Server-side or client-side
- Rate limiter based on which properties:
- User ID
- IP, ...
- The rate limiter is in a separate service or implement in the application code?
- Note: if interviewer said it's up to you, we then ask if the rate limter needs to support fault tolerant.
- If so it's better to separate the rate limiter to the API servers, in the case the API server has any problem, it doesn't affect our rate limiter.
- Note: if interviewer said it's up to you, we then ask if the rate limter needs to support fault tolerant.
Step 2. Propose high-level design
Where to put our rate limiter?
- Client-side: on client-side it's very easy to malform the rate-limiting. And also we're not always have the control over the client implementation. So this is not recommended
- Server-side:
- Rate limiter at the API server.
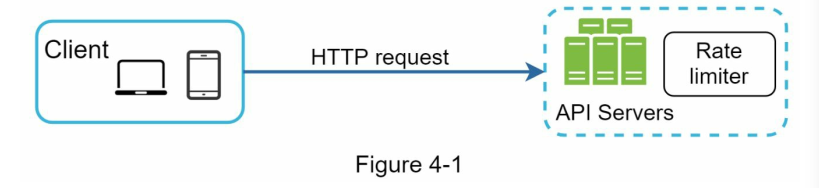
- Rate limiter as middleware
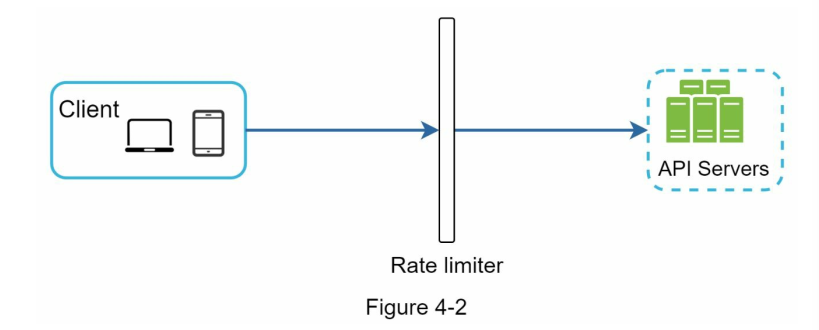
- This is more recommended as in the future we can extend this service to do SSL (Secure Sockets Layer) termination, IP whitelisting, serving static content, ...
- Rate limiter at the API server.
Which algorithm should we use?
- Stable traffic:
- Bursted traffic:
High level architecture
In a nut shell, we need to store the counters to count the number of requests to see if we need to reject. To do this, using a database will be slow and inefficient.
Redis is a popular way to implement rate limting, using its supported commands: INCR (increase the counter by 1) and EXPIRE (expire the counter)
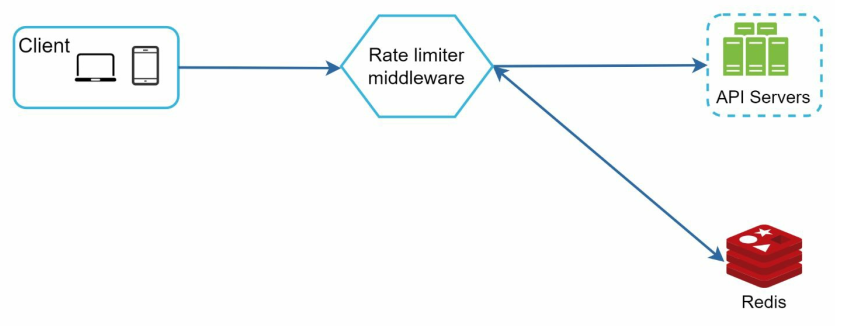
As a result, the rate limiter middleware can communicate through Redis together for efficiency.
Step 3. Design deep drive
Rate limiting rules
These example are from Lyft Rate-limiting framework. In the interview, we should follow this structure because it's industry standard. These rules are often store in disk file to fetch and read.
Why do we do this? Since we dont have to change the application code every here and there. The configuration should be from file if we need to adjust the rate limiter, the structure is highly scalable.
sequenceDiagram
participant App as API Gateway / App
participant RLS as Rate Limiter Service
participant Rules as Rule Config (YAML/JSON)
participant Redis as Redis Server
Note over RLS, Rules: Initialization Phase
RLS->>Rules: Load rules into local cache
Note over App, Redis: Request Phase
App->>RLS: checkLimit(domain="messaging", descriptors=[{key:"msg_type", value:"marketing"}])
RLS->>RLS: Match descriptors against local Rule Cache
Note right of RLS: Found Rule: 5 per day
RLS->>Redis: EVAL sliding_window.lua (key, window, limit)
alt Under Limit
Redis-->>RLS: return 1 (Success)
RLS-->>App: 200 OK (Proceed)
else Over Limit
Redis-->>RLS: return 0 (Fail)
RLS-->>App: 429 Too Many Requests
end
We can use the following json rules. This example limit the number of marketing messages to 5 per day.
domain: messaging
descriptor:
- key: message_type
value: marketing
rate_limit:
unit: day
requests_per_unit: 5
or with this example, we only allow 5 login authentication per day from the same user
domain: auth
descriptor:
- key: auth_type
value: login
rate_limit:
unit: minute
requests_per_unit: 5
Exceeding rate limits
Will return 429-Too-Many-Requests. To let the client know that they're being throttled, we can use the following headers:
X-Ratelimit-Remaining: remain number of allowed request within the time window
X-Ratelimit-Limit: how many calls client can make per time window
X-Ratelimit-Retry-After: number of seconds to wait until you can make a request again without being throttled
Detail design:
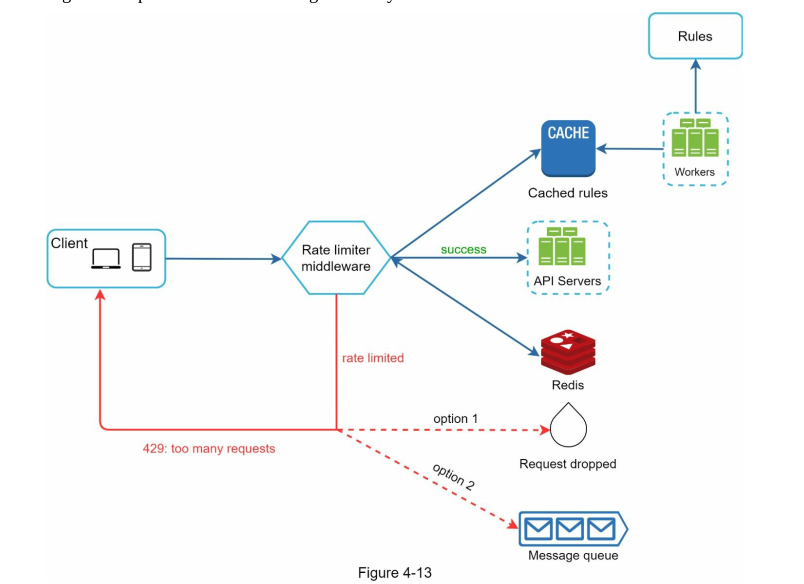
Rules are stored in disk, worker will pull the rules from disk and store in cache for our rate limiter to read. This can be done via Cron or some message queue (RabbitMQ) depends on our choice. This rules here are rarely changes and normally constant so we don't need a database.
- Disk is slow, cache is fast (memory)
To scale, we can consider store rules in blob storage.
Consider in distributed environment
Race condition:
When different rate limiter trying to read values from redis the same time, there could be a race condition. For Redis, single operation is atomic, but if multiple instances read and write at the same time there would be a Race Condition happen.
For example:
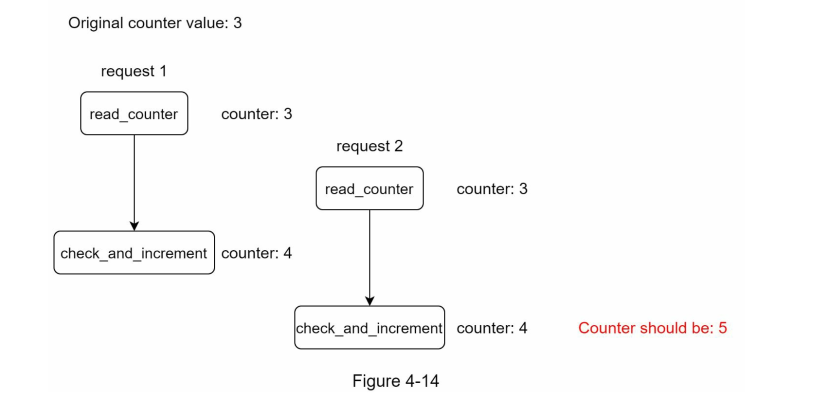
Solution:
- Lock (could slow down the system)
- Use Sorted Set data structure in Redis with lua script ^863360
- In redis, lua script will always be atomic for execution
- Rate limit implementation with Redis
Synchronisation:
Because we have multiple rate limiters, client 1 can send data to rate limiter 1. And client 2 send data to rate limiter 2. Therefore rate limiter does not work properly because rate limiter 1 does not have any information of rate limiter 2 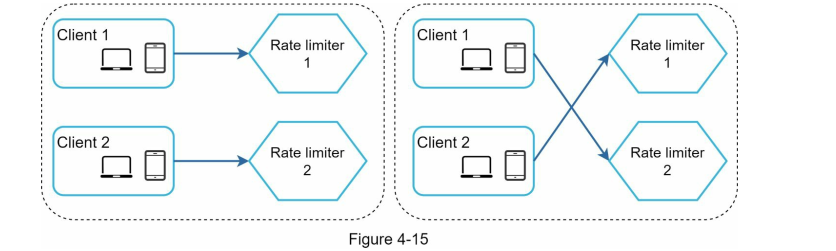
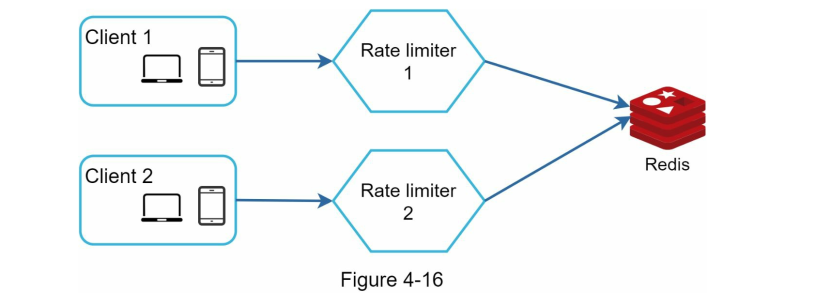
Solution
- Sticky session (not scalable, not flexible)
- Redis
Step 4: Extra
Performance Optimization
- We can use multi-data center model to address latency issue. Connection will automatically be routed to the closest edge server.
- Synchronise data with eventual consistency model (NoSQL).
Monitoring
- We need to capture log to decide if we need to change the rate limitor algorithm. We need to capture how many request are dropped, and weather we have sudden increase in traffic.
Hard or Soft rate limiting
- Hard: number of requests cannot exceed the threshold
- Soft: requests can exceed the threshold for a short period of time
Layer to rate limit
- Beside HTTP (layer 7), we can also apply rate limit by IP addresses (Layer 3)
Client Side To avoid being rate-limited
- Use caching
- Backoff-retry to avoid sending too many requests within a short time frame.