Anatomy Of An Index
Leaf nodes
Index Leaf Node is to hold the index mapping to the table. It's a double linked list.
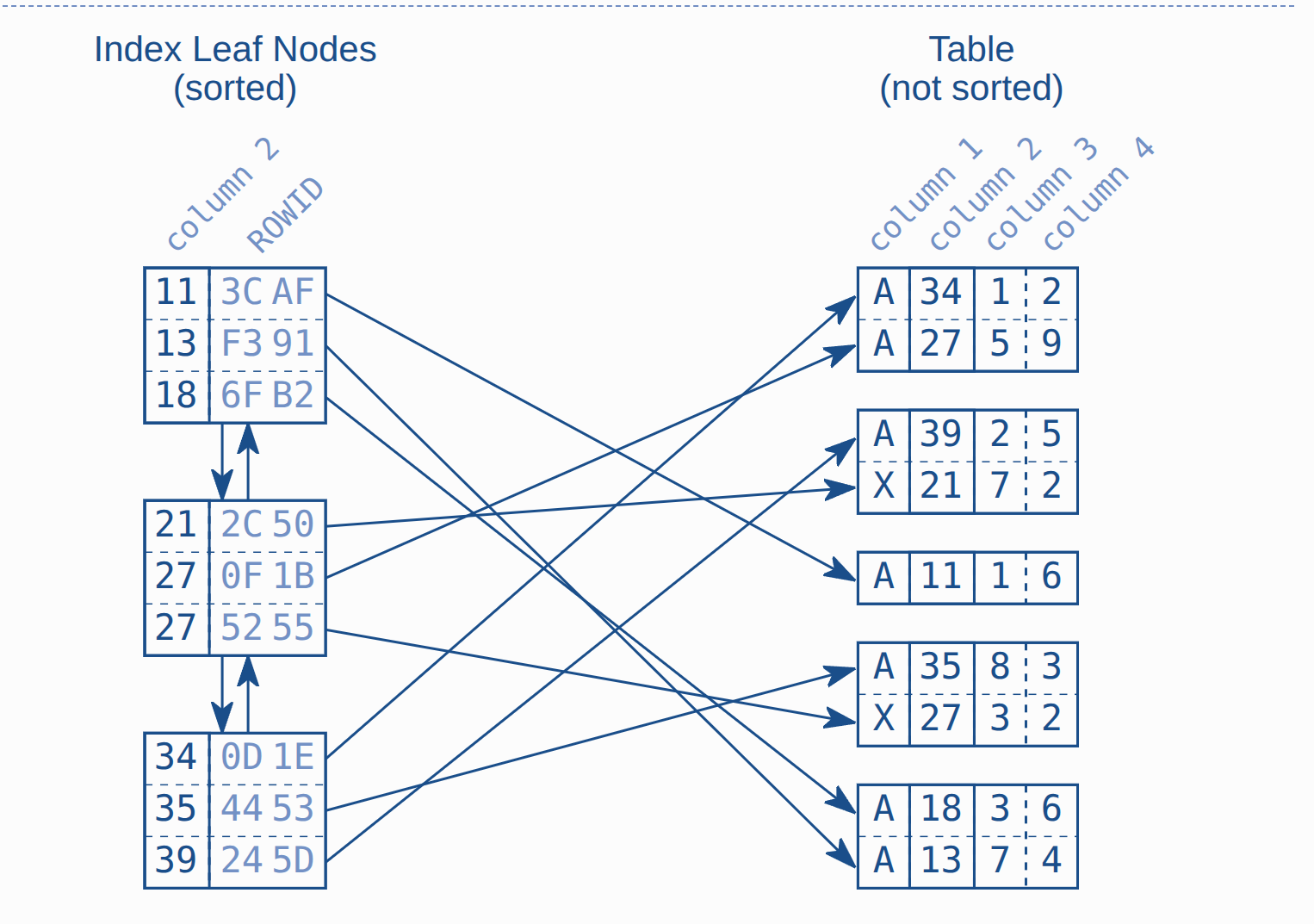
The leaf node will store the index, rowid (rid) which map to the actual role.
B-tree
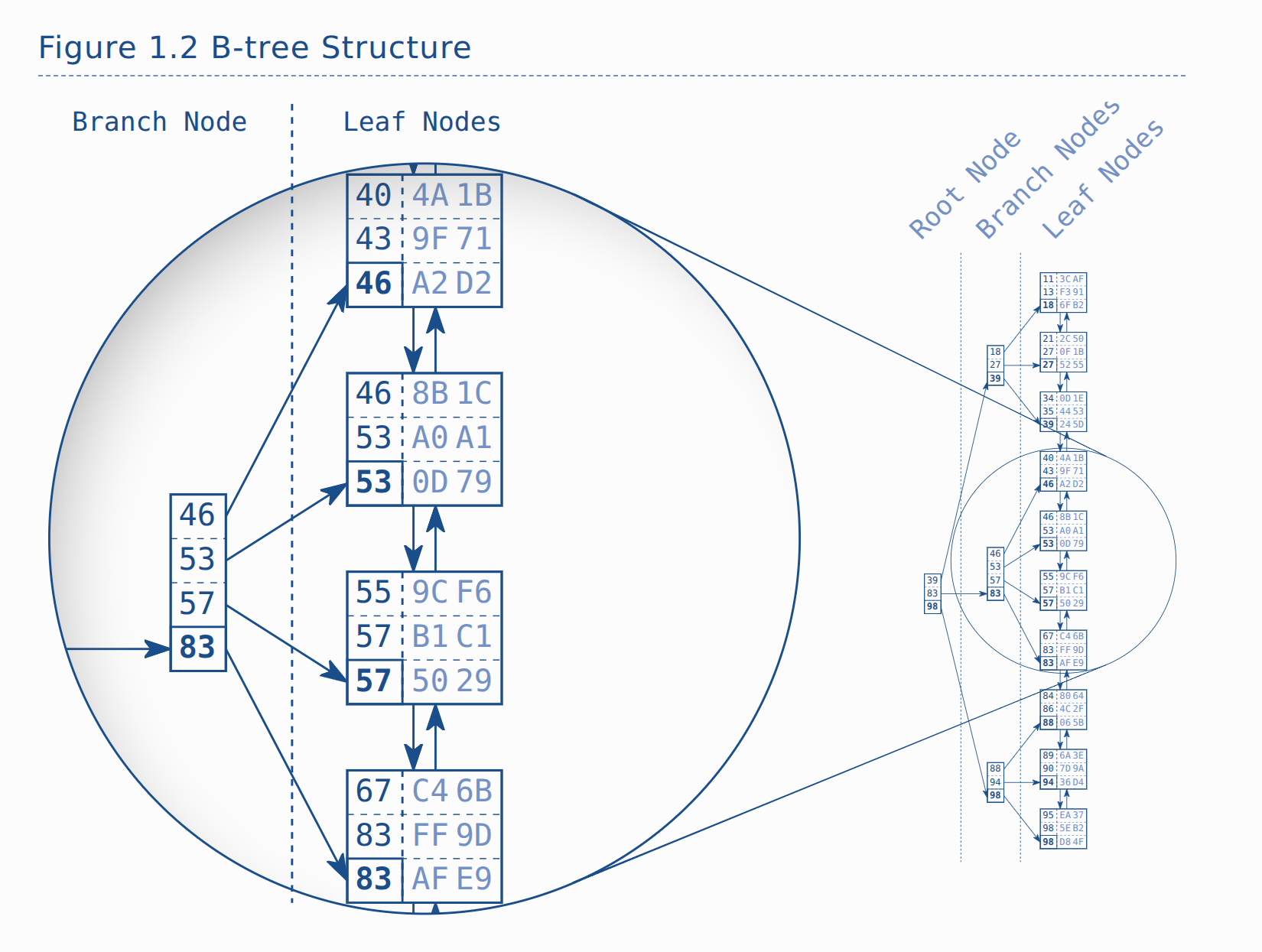
- Each of the branch node or root node entry will store the biggest value in the leaf node.
- The tree is balanced because the depth is equal in all position
- Once created, database applies every
insert, deleteandupdateto the index to keep the tree in balance.- lead to maintenance overhead for write operation
B-Tree Traversal
For example looking for node 57
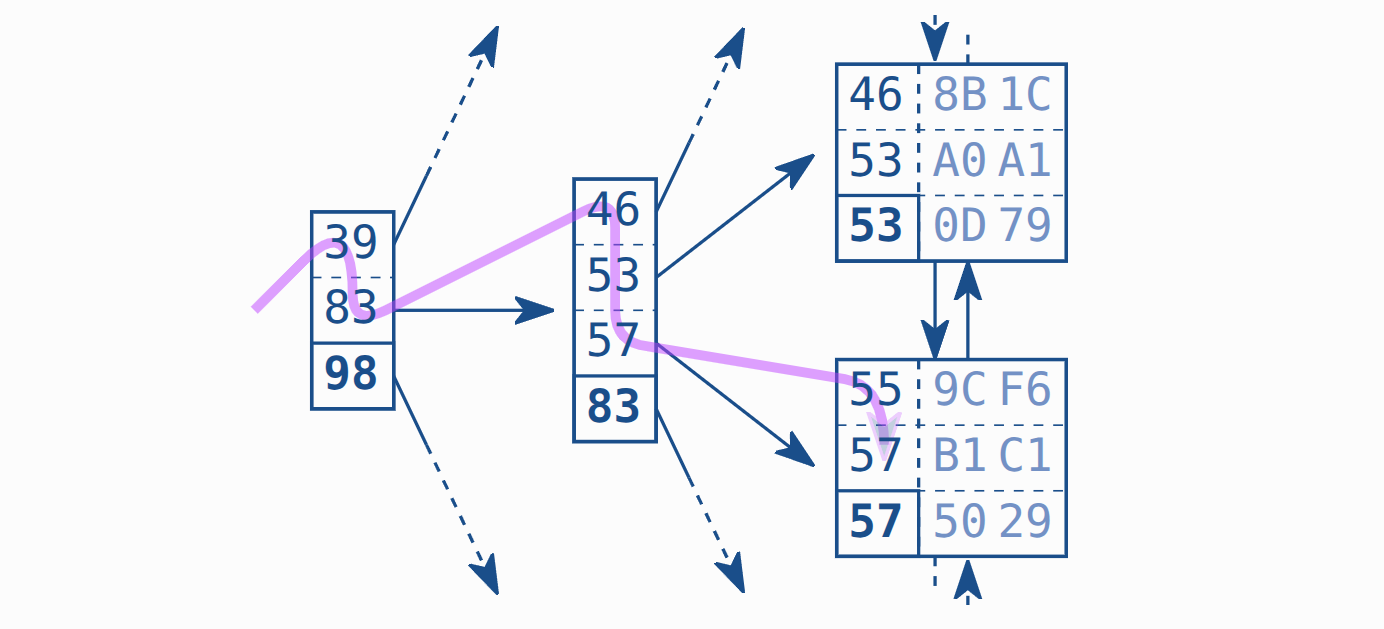
It will find which value >= 57. And then keep moving on to lower leaf.
Slow indexes
The index can be slow as well. Given the image above, there could be another leaf node of 57 as well. If so, the database also need to check that node before giving the answer.
An index lookup perform 3 steps
- Tree traversal (Like above)
- Following leaf node chain
- Fetching the dtable data
The Tree traversal is the only step that benefits from indexing because we search on index depth. Step 2 and step 3 could cause a slow look up
There are 3 operation to describe index lookup
INDEX UNIQUE SCAN: perform tree traversal onlyINDEX RANGE SCAN: perform tree traversal and follow leaf node chain to find all matching entryTABLE ACCESS BY INDEX ROWID: After the index, this operation is to actually retrieve the row. This is done for every matched record from previous index scan operation
The INDEX RANGE SCAN is often the step that cause performance issue