Design A Search Auto Complete System
High level design
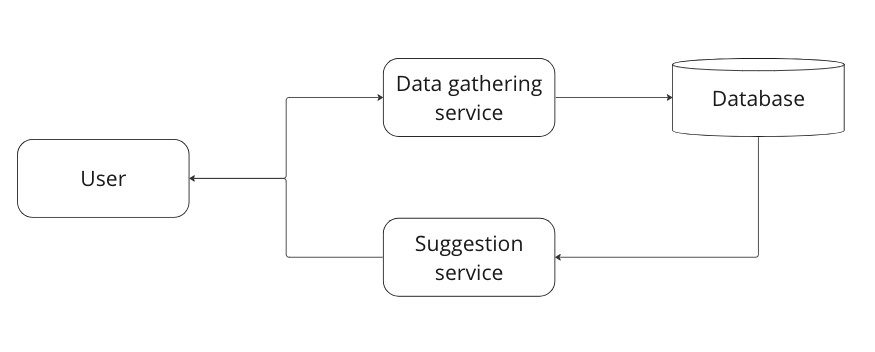
When the user type in the search, the user then talks to our data gathering service. This service will save the keyword into our database
Upons user typing, suggestion service can query the database and return back to the user.
Data gathering service
Purpose: store the frequency of each word for popularity
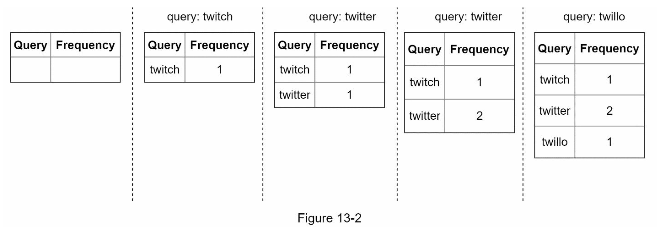
Data gathering service can be simply designed as a key-value storage. For example for each query we can put them into the frequency table
Query service
Once we save our frequency into the database, we can then have the following format:

To get the top 5 keywords, we can simply
select * from frequency_table where query like `prefix%`
order by frequency desc limit 5
In term of database, we can choose a key-value store database like Redis, DynamoDB
This is an acceptable solution, however once our database get bigger it will get bottle necked
Deep drive design
Trie datastructure
For a fast search, we might need to consider using Trie datastructure. The recap, the datastructure looks like following
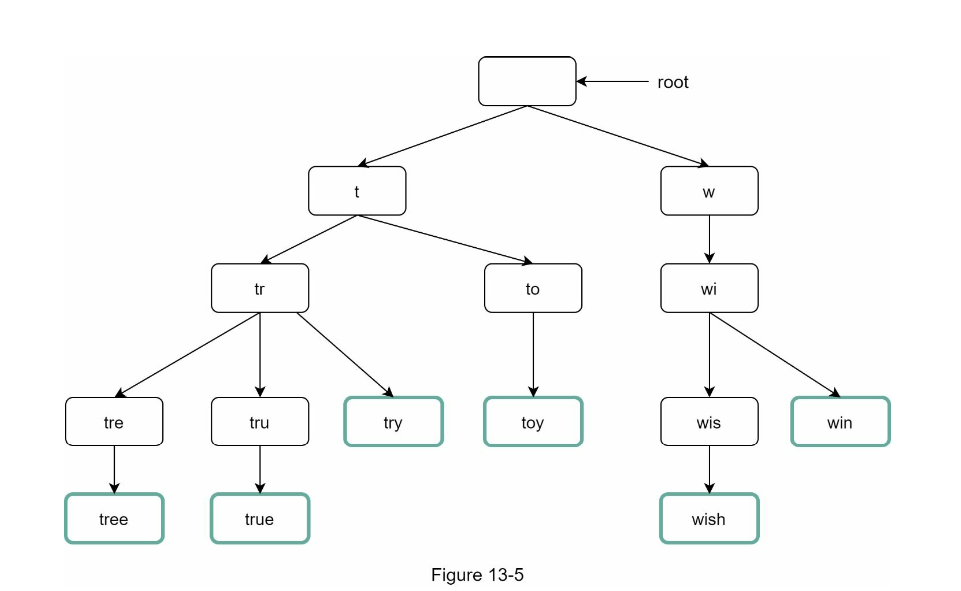
Now we need to find a way to store the frequency of each node. One way to do it is for each hit, we store the frequency in the leave node
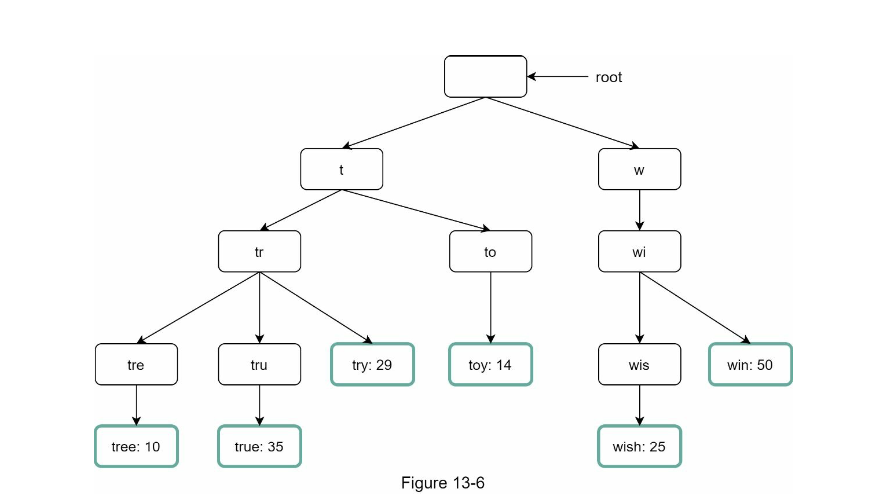
The time complexity is $O(prefix)$ for searching a prefix, however since we need to get the top 5, we need to traverse through all the children of that prefix
So time complexity is $O(p + n + c\log{c})$ where
- $p$: prefix length
- $n$: number of all nodes in the tree
- $c$: number of completion associated with the current prefix
- $c\log{c}$: we need to sort these completion to get the top $K$ completion
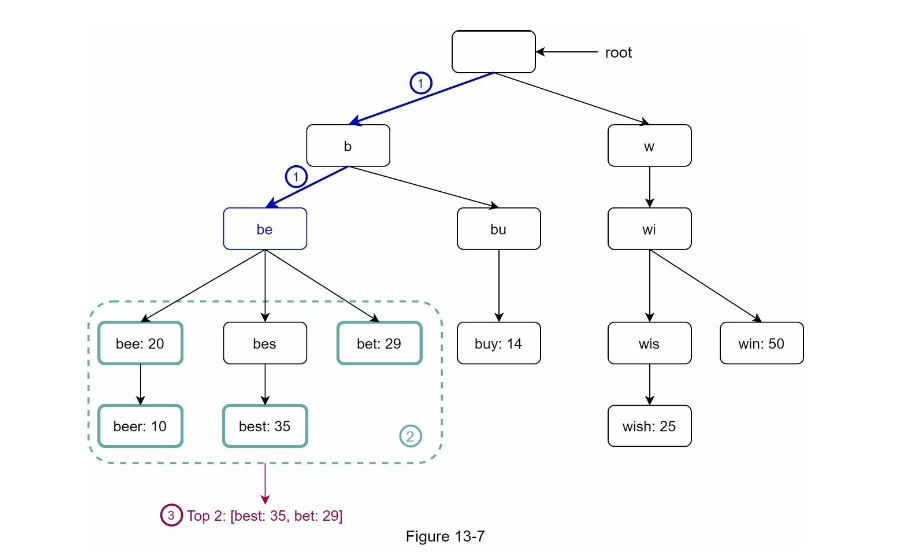
The main bottle neck here is $O(n)$ where when you traverse down the prefix node, you have to visit every single one of its children to find all the completion. Therefore worst case is a single node of many children $O(n)$
Optimisation
We can optimise by introducing a cache at the parent level.
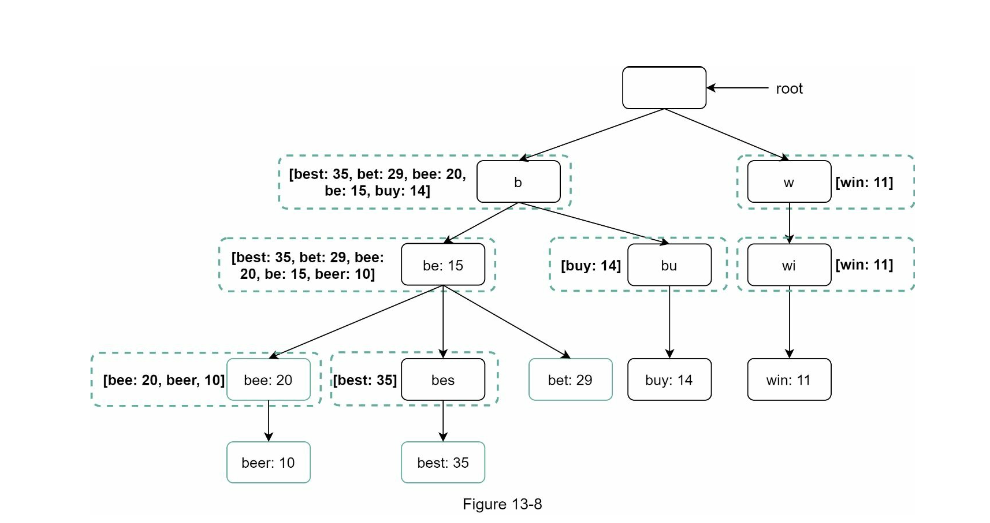
At each node, it will have a cached result of this cache, therefore we can just return immediately. As a result, the time complexity reduce to $O(prefix + c\log{c})$ because we don't have to do the $n$ traverse anymore
More over, we can limit the length of the prefix, and the top $k$ element. Therefore we can have to
$O(prefix + c\log{K})$ but since prefix and K are constants it reduces to $O(1 + 1)$ = $O(1)$
Update the trie
Updating the trie with the cache is tricky, there are 2 options we can consider:
- Update the node values
- Build a new trie and replace the current trie with the new trie
In our system, since it's not required to do real-time suggestion (considering Google is not even real time). We can just update the top result weekly or so on with a new try.
With option 1 we can afford real-time, however rebuilding a trie and updating in each node for caching is very expensive and complex.
We will go for option 2 as the system doesn't need real time. Building a new try from scratch is easier and less overhead.
Data gathering service
In the previous sytem, data gathering service insert in the table directly.
However with millions of user active daily, this will overload our database significantly. As a result, we can have the suggestions values come in as log file and a list of worker can then pick up and handle database insertion later
To fasten up the process of data gathering, we can save the record as log file since log file is very fast and you can just append to the log. For example:
Hello, 22/09/2023, 15:00:31
Cat, 22/09/2023, 16:01:31
Try, 22/09/2023, 20:19:31
Java, 22/09/2023, 21:00:31
Hello, 22/09/2023, 21:01:31
Java, 22/09/2023, 21:01:32
Data aggregation service
From the log above, we can start aggregate our data to look like the following
Hello, 2
Cat, 1
Try, 1
Java, 2
This is to feed into our Trie Builder worker to build the Trie. For data aggregation, we can consider Map-Reduce architecture.
Architecture
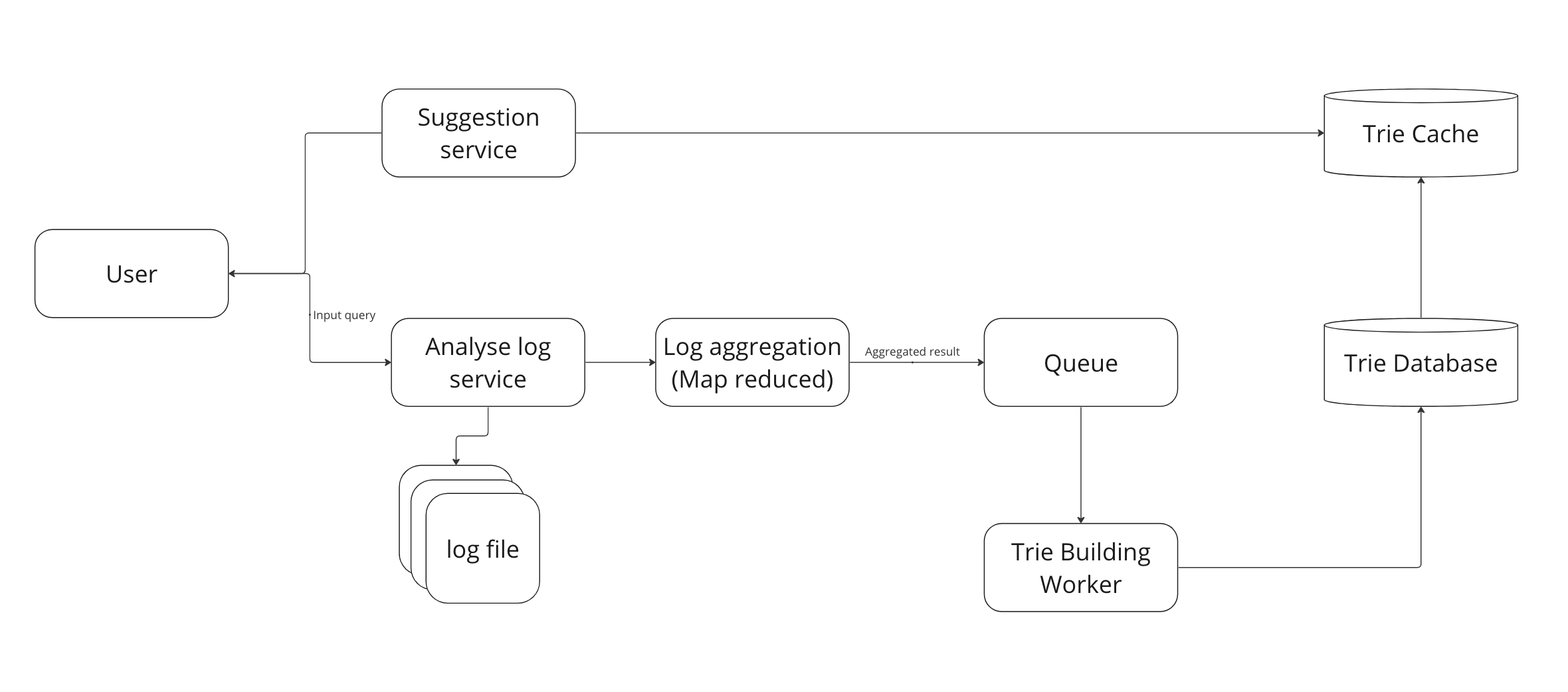
- User input the query, suggestion service will fetch data from Trie Cache to suggest to the user
- If the information is not cached, we then fetch from Trie database
- For each query, we append it into the log file from Analyse log service
- Log aggregation service will aggregate the logs using Map-Reduce pattern. These aggregation result will be put inside a queue for our Trie Building Worker to build
- Trie building worker pick up aggregated result inside the queue and start building Trie. These trie will be then saved into database
- A snapshot of trie database can be saved into Trie Cache for quick fetch result
Database choices
For our Trie database, we have two options:
- Document store
- Store the trie as JSON and implement Serialisation and Deserialisation to deserilise the class.
- Cons:
- Deserialise might be complex and slow if the trie structure is big
- Lookup for a certain word in the database is expensive, have to deserialise every time
- Pros:
- Intuitive and human readable
- As key value store
- Store each node of the trie as the key value store. Which the key is the node and the value is the cache result
- Cons:
- If trie is big storage might be a lot
- Pros:
- Easier to look up with $O(1)$ time complexity for the given prefix
For this reason, let's choose 2. since performance is important for our use case.
We can save the trie as following:
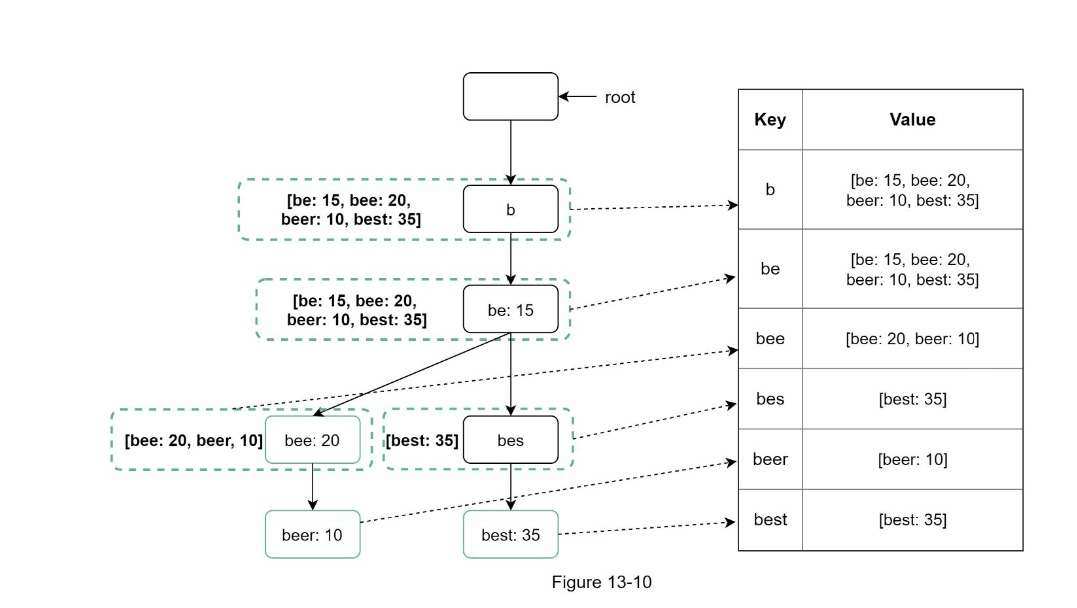
Filter unwanted keyword
Note: In the book version put like this
However, if saving like this it might affect the result of our top K queries. What if the unwanted keyword is in our top K, by filtering in the return, we essentially returning less than k values to the users.
I think filtering should be done in data aggregation service which we can filter out the unwanted key-word there and not keep track in the system at all.
Scaling storage
For scaling our key-value storage, we can use Database Sharding. Which we can have 26 servers of shard from a-z where each server will store a particular starting prefix
If we want to store more than 26 servers, we can shard using 2 characters for example
aa - ag,ah - an,ao - au,av - az
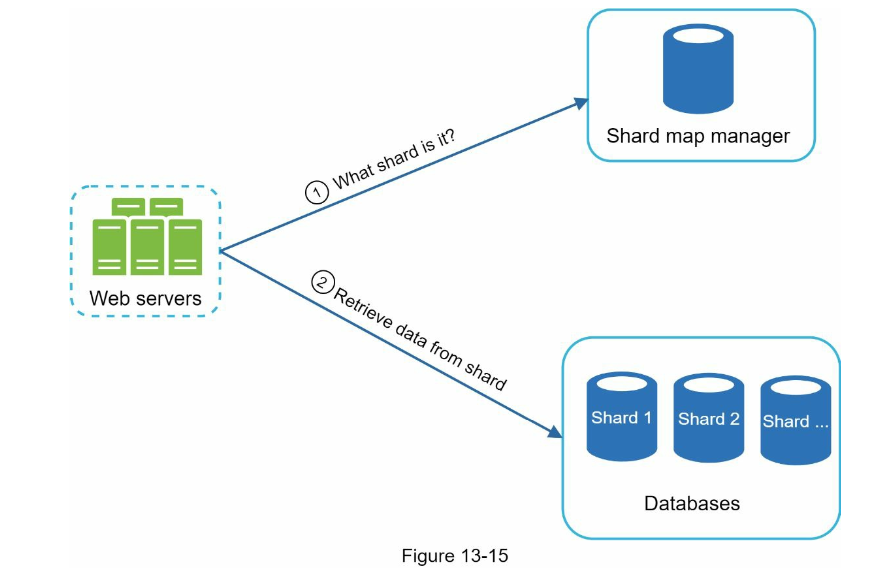
Shard joining
We will have a lot more letter starting with c instead of x therefore it will create a hot-partition. As a result, we can choose to join a few shard together
Shard manager
To query the shard, we can try to query our shard map manager database which contains the shard for the keyword we're looking for and query that database server